
My Snowflake Set up with Terraform
I have been working with Snowflake since 2016 when I proposed and chose to bring it into Rent the Runway to replace our very painful on premise Vertica implementation (yes we had it in a data center in NJ). Since then, Snowflake has grown considerably and is now one of the leading Data Warehouse offerings.
After implementing data warehouses at several companies and having lots of conversations with some very smart folks, I've learned some things along the way. I've found it is a really good idea to think about up front how I want to segment responsibilities and permissions for databases. I want to decide what types of data to store in different places and to build roles + permission grants to enforce those decisions.
My Best Practices Assumptions for segmenting data:
Best practice for running a cloud data warehouse is to build separate repositories for:
- raw data from source systems and providers
- schemas where data is regularly transformed/generated and documented to be consumed for reporting and analysis
- area to data exploration, modeling, and experimentation
To ensure that these logical areas are used for their defined purposes, we can create specific roles and permissions for each.
Logical set up of Databases with Role Permissions
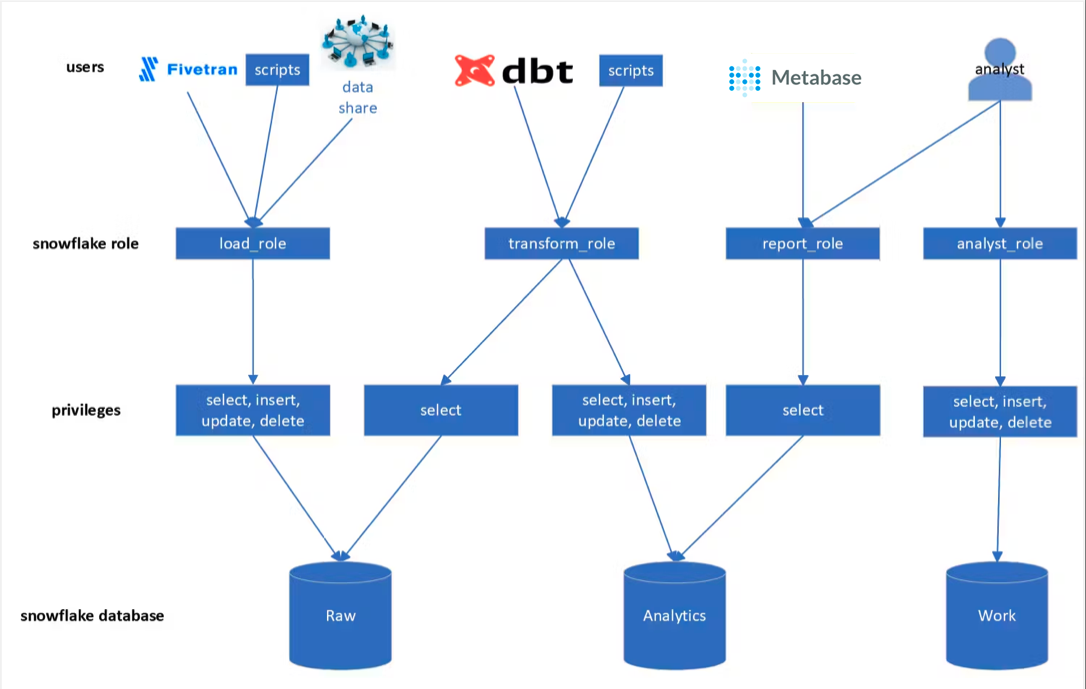
| database | functional description | privileges |
| Raw |
|
|
| Analytics |
|
|
| Work |
|
|
Other key assumptions with this set up:
- Each Snowflake Role has its own dedicated compute (Snowflake Warehouse).
For instance the LOAD_ROLE can only run on a warehouse named LOAD_WH. - The Raw database should contain a schema for each source system.
For example, if we are syncing data from our ecommerce site with a Mongo backend, we would name the schema as MONGO_ECOMMERCE. - In the Analytics database, we define 5 schemas:
- src: holding dbt models of data that has been lightly transformed from the original source data. Here we may flatten nested variant data into a relational model.
- trans: schema for intermediate dbt models
- rpt: holding dbt dimensional models that drive our BI reporting
- export: holding tables/views that are for data to be exported to systems outside of Snowflake
- db_stats: metadata about our dbt models like total runtime, last runtime, number of rows added incrementally, etc - The specific tools in the diagram above are meant to be examples for certain roles:
- Fivetran to sync raw data from source systems into RAW (could be meltano, airbyte)
- dbt to create models in ANALYTICS (could be ML scripts via dagster/airflow)
- Metabase to read from ANALYTICS for BI (could be Looker, Tableau, Superset) - You need to consider the processes for Development and Testing of Pipelines + Models. This diagram does not describe how I would approach these topics.
Snowflake configuration management with Terraform
Terraform (created by Hashicorp) is an open-source infrastructure as code software tool that enables you to safely and predictably create, change, and improve infrastructure.
Chan Zuckerberg terraform provider for Snowflake
This is a terraform provider plugin for managing Snowflake accounts:
GitHub - https://github.com/Snowflake-Labs/terraform-provider-snowflake
Documentation available here:
Terraform Registry
We can use this framework to manage objects in snowflake such as:
- databases
- roles
- schemas
- user accounts
- permission grants
Github repo with my terraform configuration for this set up
https://github.com/jaygrossman/snowflake_terraform_setup
PLEASE NOTE: This scope for this repo does not include the terrafom configuration to set up snowflake stages, functions, and file formatters. These objects often have more dependencies and require more advanced configuration, so I may plan to dedicate future blog posts to explaining the details.
Folks who this would not have been possible without:
 |
 |
 |
| Collin Meyers | Rob Sokolowski | Tim Ricablanca |