
Optimizing spend in Snowflake

Since about 2016, I have introduced Snowflake at two of my day jobs (Rent the Runway and Luma Financial Technologies) and have witnessed the platform's considerable evolution. As with any hosted SaaS platform, it is very important to understand both how the solution is architected, how users interact with it, and how it is priced.
A very common concern among dats folks is that their Snowflake bills grown considerably as their use cases for it expand. A few months ago I saw this post on LinkedIn:

I think the suggested action in the post could potentially lead to a very small cost savings, but I suspect there are more impactful areas we can look at to keep our Snowflake costs down. I thought it would be helpful to detail out:
- How Snowflake's billing works
- Areas where you can look to optimize
How Snowflake's billing works
I found an area and a pdf where Snowflake lays out their costs, so I'll do my best to summarize with commentary below.
One of the main selling points for Snowflake is that they do a really good job of separating storage of the data, the compute that runs actions on the data (queries, transformations, etc.), and the cloud services that run the platform's engine. So their pricing is based on 3 components:
- the volume of data stored in Snowflake
- the compute time used
- the cloud services that are used
1. Data Storage Pricing
Data storage pricing is based on the daily average data volume (in bytes) stored in Snowflake, including compressed or uncompressed files staged for bulk unloading or loading, historical data maintained for File-safe, and data kept in database tables. Snowflake automatically compresses and optimizes all table data, then calculates storage usage based on this compressed file size. The monthly charge for data storage in Snowflake is set at a flat rate per terabyte (TB). However, the precise amount per TB paid depends on the platform (Amazon Web Services (AWS), Azure, or Google Cloud Platform (GCP)). Typically, Snowflake charges a minimum of $25 and up to $40 per terabyte of data stored in its US system.
For instance, if a Snowflake account is a capacity AWS in us-west-1 snowflake account and the price is $25 per Terabyte per month.
It is worth noting that the cost of storage in Snowflake is based on the amount of data stored in the account. This includes data stored in database tables, files staged for bulk data loading, and clones of database tables that reference data deleted in the table that owns the clones
2. Compute Pricing and Credits
Snowflake bills compute with credits - the unit used to measure how much billable compute (virtual warehouses) you consume. A Snowflake credit is used only when resources are active, such as when a virtual warehouse is currently running, when loading data with Snowpipe, or serverless features are in use.
A virtual warehouse contains one or more computing clusters for performing queries, loading data, and other DML operations. Virtual warehouses use Snowflake credits as payment for the processing time they use. How many credits you use depends on the virtual warehouse’s size, running duration, and how many they are.
Warehouses are available in ten sizes now. Each size specifies the amount of computing power a warehouse can access per cluster. By expanding a warehouse to the next larger size, its computing power and credit usage doubles per full operational hour. Check this out:
The credit pricing rate depends on the Snowflake edition you use: Standard, Enterprise, or Business-Critical. Each edition offers a different set of features.
The table below shows the Snowflake Credit usage and estimate of the USD cost per hour assuming one credit costs $3.00 (I have found you can get a better rate with a year long commitment):
| Size | Credits/Hour | Cost/Hour |
| XSMALL | 1 | $3.00 |
| SMALL | 2 | $6.00 |
| MEDIUM | 4 | $12.00 |
| LARGE | 8 | $24.00 |
| X-LARGE | 16 | $48.00 |
| 2X-LARGE | 32 | $96.00 |
| 3X-LARGE | 64 | $192.00 |
| 4X-LARGE | 128 | $384.00 |
| 5X-LARGE | 256 | $768.00 |
| 6X-LARGE | 512 | $1,536.00 |
Some details to note:
- Warehouse only uses credits while running — not when suspended or idle. Snowflake does not charge for idle compute. In fact, it offers a quick start/stop feature to suspend resource usage whenever you choose or automatically with user-defined rules, such as “suspend after five minutes of inactivity”.
- Credit usage per hour directly correlates to the number of servers in a warehouse cluster.
- Snowflake bills credits per second — with a minimum requirement of 60 seconds. Meaning, starting or resuming a suspended warehouse incurs a fee of one minute’s worth or usage. Also, resizing a warehouse a size larger costs a full minute’s worth of usage. For example, resizing from Medium (four credits per hour) to Large (eight credits per hour) has an additional charge for one minute’s worth of four additional credits.
- But after a minute’s usage, all subsequent usage resumes on a per-second billing as long as you run the virtual warehouses continuously. Stopping and restarting warehouses within the first minutes leads to multiple charges because the one-minute minimum charge applies each time you restart.
- Operations, such as suspending, resuming, increasing, and decreasing are nearly instantaneous, So, you can precisely match your Snowflake spending to your actual usage, never worrying about capacity planning or unexpected usage.
3. Cloud Services Pricing and Credits
Snowflake cloud services comprise a set of tools that support the main data storage and compute functions. The services include metadata and infrastructure management, SQL API, access control and authentication, and query parsing.
These services are, in turn, powered by compute resources, meaning cloud services consume Snowflake credits, just like virtual warehouses. However, Snowflake only bills cloud services that exceed 10% of your daily compute resources usage. Thus, the 10% adjustment automatically applies on each day, based on that day’s credit price.
For example, if you’ve used 120 compute credits and 20 cloud services credits on a particular day, the adjustment will automatically subtract 10% off the compute credits (120 X 10% = 12) for that day. So, your billable credits will be:
Total used cloud services credits for the day (20) – adjusted amount (12) = 8 credits billed.
If your cloud services amount is less than 10% of your daily compute credits amount, Snowflake charges you based on that day’s cloud services credits.
For example, if you’ve used 100 compute credits and 8 cloud services credits, you’ll have used 8% of your compute credits in cloud services credits. In this case, Snowflake will automatically count 8 cloud services credits as the day’s cloud services usage.
Areas where to optimize
Snowflake is both robust and complex platform. With that, the good and bad news is that there are quite a few options/opportunities to consider that can affect your spend.
1. Look at your spend & consumption
Before I look to optimize, I want to understand my current consumption vs. my budget. You can see this in Snowflake's GUI using the ACCOUNTADMIN role:
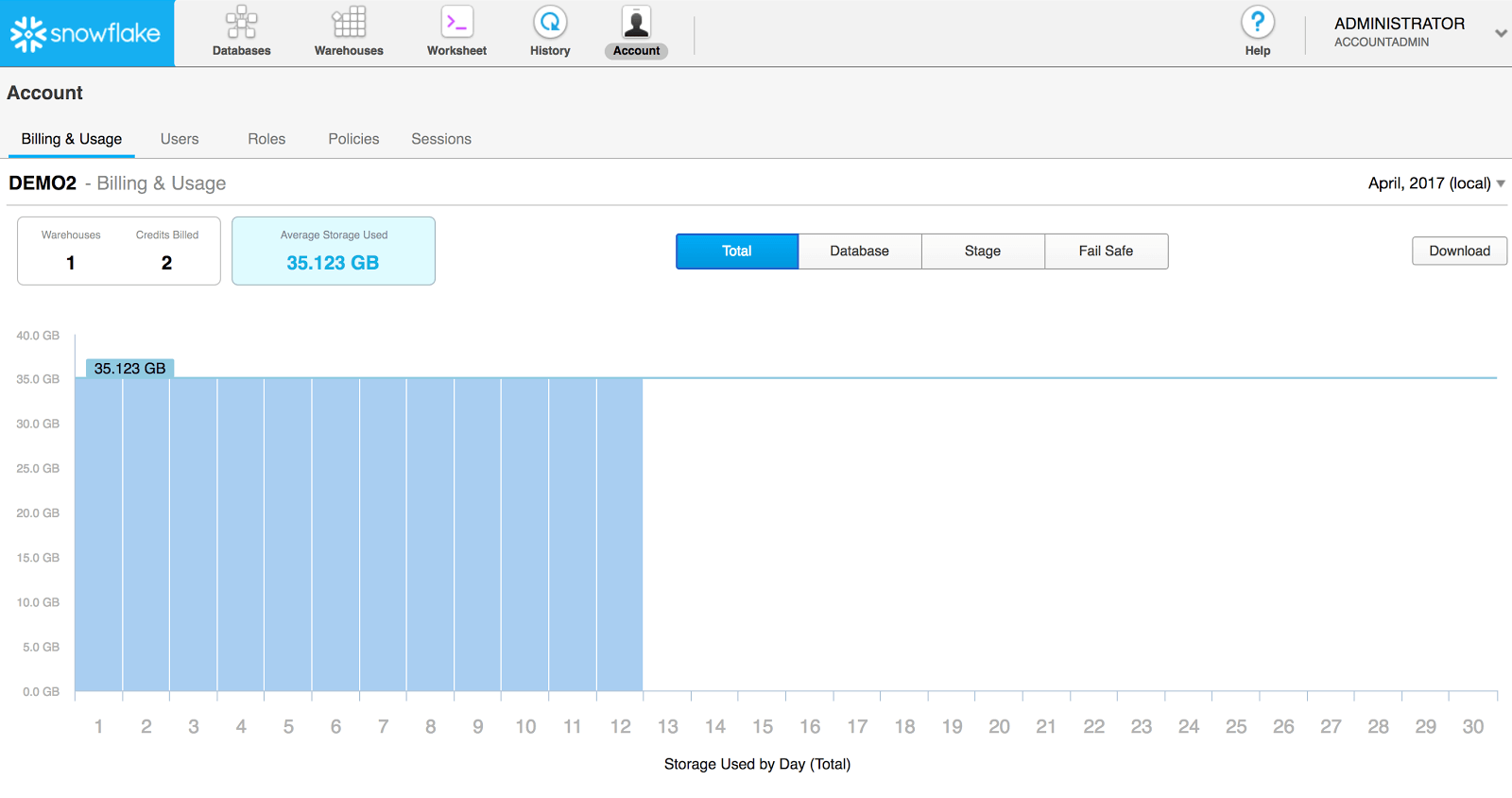
A resource I found for monitoring spend is a dbt package from SELECT:
https://github.com/get-select/dbt-snowflake-monitoring
2. Don't do things you don't need to!
Do I have processes running to create calculations, tables, or views that no longer add value?
A lot of analytics and data science is doing feature exploration, but we don't always clean up after our experimentation and disproved hypotheses. This can consume a bunch of credits ongoing basis when they take a lot of resources to create, and morse so if they exist in multiple environments (for testing, CI/CD).
Am I running processes more often than I need to?
As an example - when the models are based off data that we get daily (such as closing stock values), it can become costly to run these many times a day. I have found using a dbt tags to limit the models are run in jobs that are limited to running daily.
Can I decrease sync frequency of my data ingestion tool?
There can be a pretty big a credit difference in sync'ing data ever 5 or 15 minutes vs. hourly in FiveTran, AirByte, etc.
3. Data Warehouse Considerations
In general, the majority of Snowflake compute cost is the result of automated jobs. This means a huge proportion of cost is the result of transformation jobs and this should be the priority to optimize Snowflake warehouse cost.
Segment your workloads by warehouses
My preference is to divide workloads in different warehouses for loading data, transforming data and for end user consumption as I previously described in My Snowflake Set up with Terraform. This way I can both configure the permission grants and warehouse size for each of these workload types. You may need to further segment - maybe by business vertical or priority of usage.
Choose the right size of your warehouses
As mentioned, the size of your Snowflake warehouse has a direct impact on your monthly bill.
Your use case will be key in deciding whether to run large or small warehouses. In general, running heavy queries on large warehouses and light queries on small warehouses is the most cost-effective way to go. Be aware queries should run twice as fast on a larger warehouse but stop increasing warehouse size when the elapsed time improvements drops below 50%.
I generally prefer to go with smaller warehouses and to define MAX_CLUSTER_COUNT parameter that will bring up additional nodes as scale is needed.
For warehouses designed to run lower priority batch jobs set the MAX_CLUSTER_COUNT = 3 and SCALING_POLICY = 'ECONOMY' to balance the need to maximize throughput with optimizing compute cost.
For end-user warehouses where performance is a priority set the MAX_CLUSTER_COUNT = 3 and SCALING_POLICY = 'STANDARD'. This will automatically allocate additional clusters as the concurrent workload increases. However, set the MAX_CLUSTER_COUNT to the smallest number possible while controlling the time spent queuing. With a SCALING POLICY of STANDARD, avoid setting the MAX_CLUSTER_COUNT = 10 (or higher) unless maximizing performance is a much higher priority than controlling cost.
Suspend warehouses that are sitting idle
If you have virtual warehouses that are inactive, you can suspend them to make sure you're not getting charged for unused compute power.
Here is an example of how you can create a warehouse (the auto_suspend parameter controls how long until the idle warehouse is suspended):
-- Create a multi-cluster warehouse for batch processing
create or replace warehouse transform_wh with
warehouse_size = XSMALL
min_cluster_count = 1
max_cluster_count = 3
scaling_policy = economy
auto_suspend = 60
auto_resume = TRUE;
Update the query timeout default value
By default, a Snowflake statement runs for 48 hours (172800 seconds) before the system aborts it.
This means that Snowflake will charge you for the time it took to compute a query that may have been initiated by mistake.
Set the STATEMENT_TIMEOUT_IN_SECONDS parameter:
alter warehouse transform_wh set
statement_timeout_in_seconds = 3600; -- 3,600 = 1 hour
Coordinating queries
You pay some money for idle warehouses (as defined by the auto_suspend parameter). There can be advantages to submitting multiple SQL jobs in parallel in a different connection running on a shared batch transformation warehouse to maximize throughput.
Warehouse Observability
To make sure you're staying within your Snowflake budget, you can use a resource monitor to suspend a warehouse when it reaches its credit limit.
A great trick is to set credit thresholds at different levels. For example, you could set an alert for when 70% credit consumption is reached and then another for when 90% of the credit consumption is reached.
use role accountadmin;
create or replace resource monitor transform_wh_monitor with
credit_quota = 48
triggers on 70 percent do notify
on 90 percent do notify
on 100 percent do suspend
on 110 percent do suspend_immediate;
4. Understand and Optimize Queries
Since credits for running queries/transformations are usually the biggest component of my snowflake bill, I generally want to understand:
1. What queries represent the biggest portion of my consumption?
2. What parts of those of those queries take the longest?
3. Can I refactor those queries better (faster + less resource intensive)?
What queries represent the biggest portion of my consumption?
I found a helpful blog post that talks about the ACCOUNT_USAGE schema (that contains details about my Snowflake usage) and how to build a dashboard within Snowflake detailing my usage. Below are some screen shots:
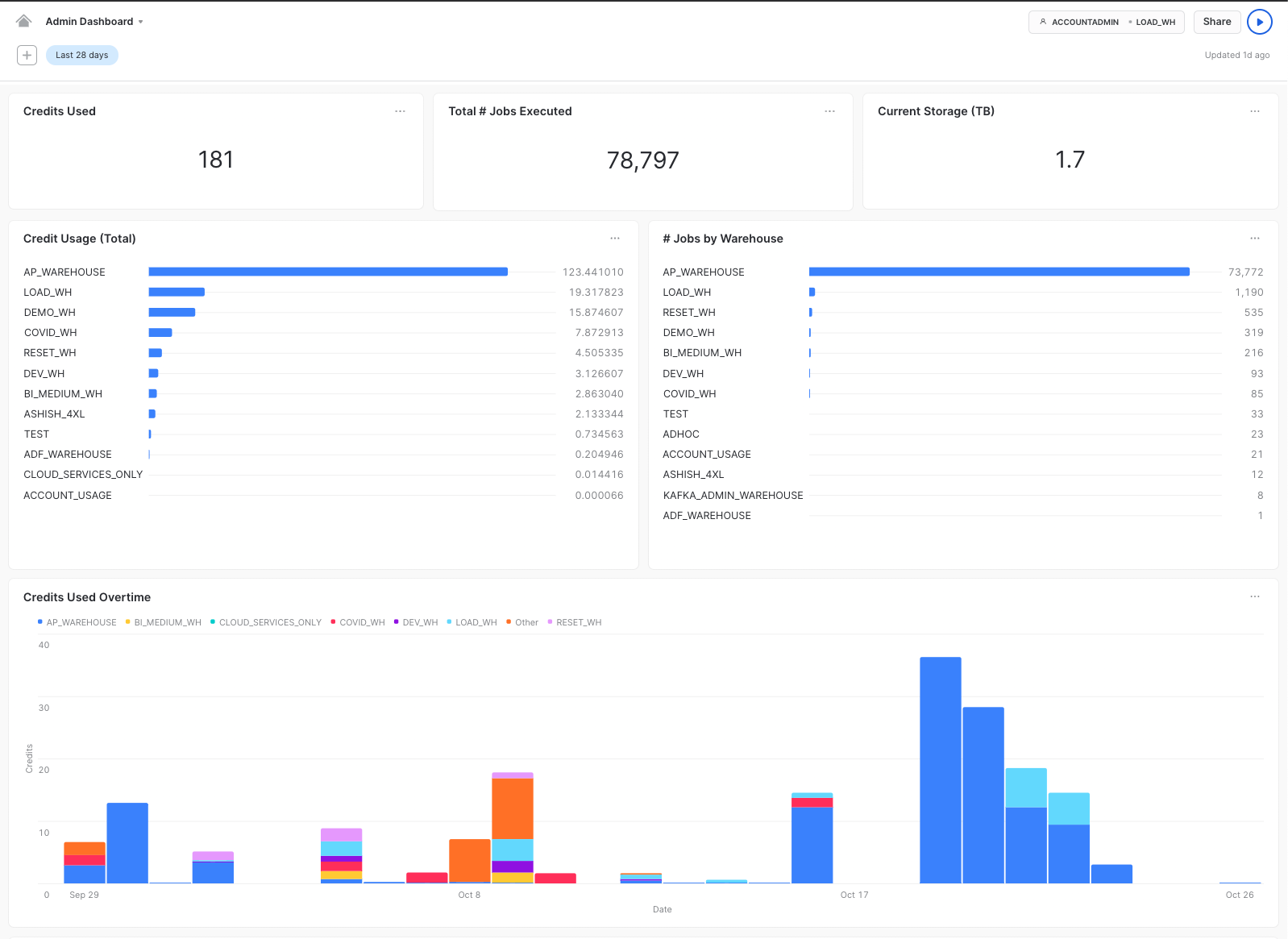
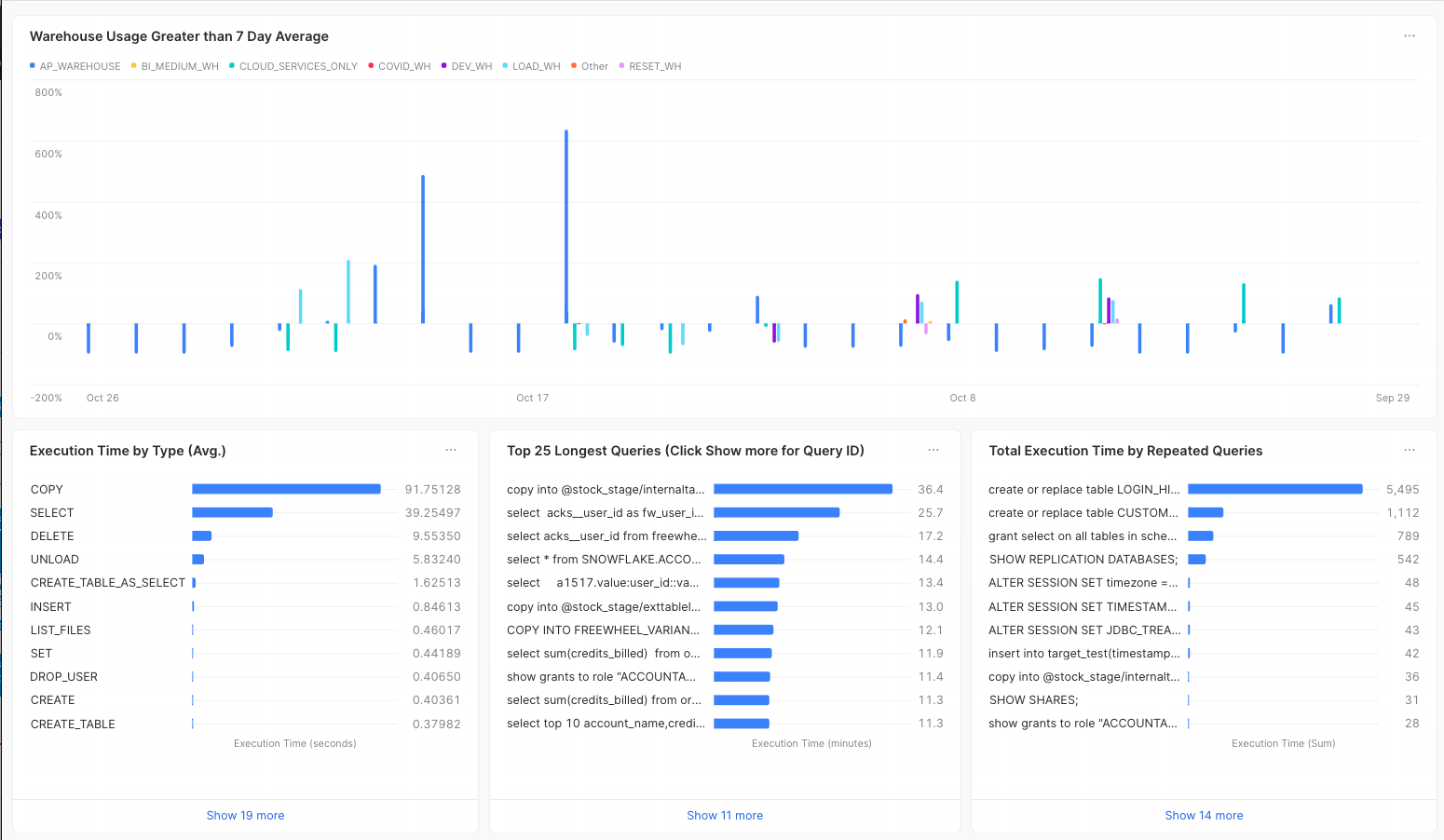
Since I am a frequent dbt user, I generally will look at the standard output after a "dbt run" for models that are taking over 60-120 seconds (shown below). Unless your data is quite large, this is generally a good indicator for a potential refactor.

What parts of those of those queries take the longest?
My friend, the Snowflake Query Profiler, is very helpful. It's probably one of my favorite features in the product.
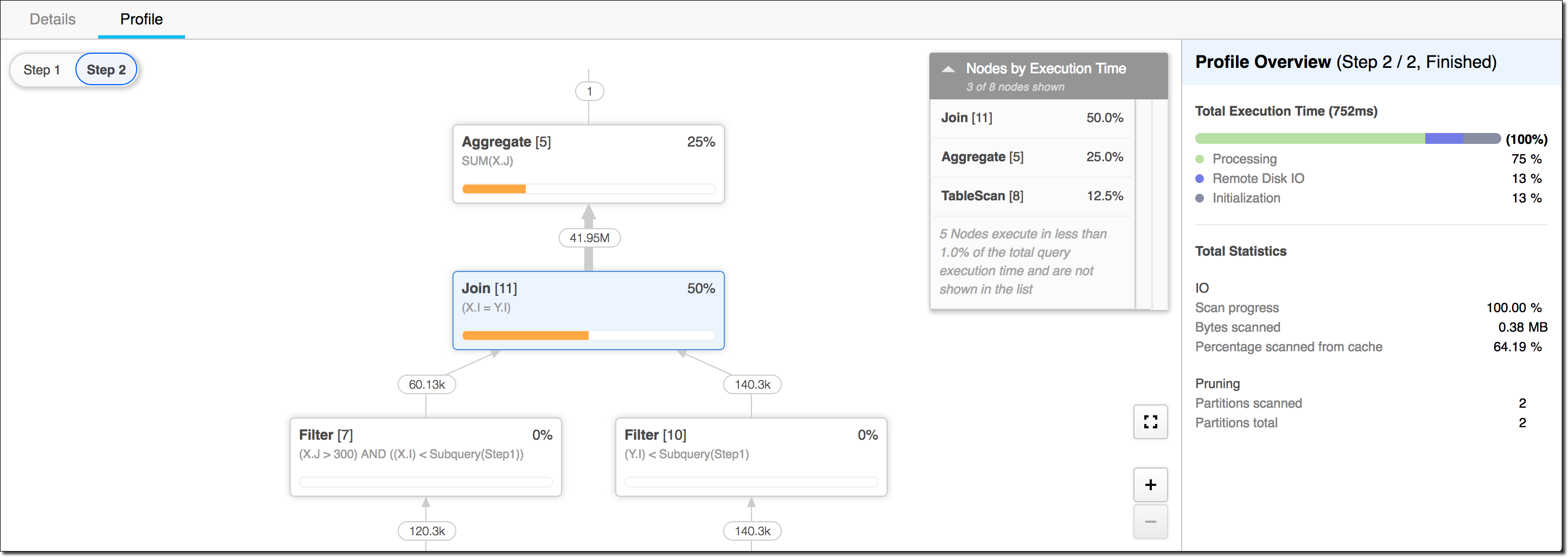
The profiler shows you in detail how it breaks down your query in order to build your requested data set. It shows the amount of time it spends on each step. This will let you know where there may be opportunities for refactor your query.
This is an excellent blog post that details more about the profiler:
https://teej.ghost.io/understanding-the-snowflake-query-optimizer/
Can I refactor those queries better (faster + less resource intensive)?
Like with most databases and infra, POORLY WRITTEN CODE MAY BE VERY COSTLY. Some things I look for that could be inefficient code to refactor:
- Where is query spending its time - on (network, processing, synchronization)?
- Is the query scanning too much data? Could you filter more efficiently or set up cluster keys?
- Is it spilling out of memory and reading from disk?
- Is the query calling too many micro partitions?
- is there an inefficient join?
- Could you rewrite it as a CTE or with UNION'ing data sets?
- Should you change the order if you are joining two tables ON multiple fields?
- Are you calling a view (or multiple cascading views) where having a materialized table makes more sense?
- Are your UDF's (functions) running efficiently? Can you do the logic in SQL (more efficient) instead of another supported language?
- Are there places where we can do incremental additions/updates instead of fully rebuilding full tables?
5. Data Storage Considerations
Use the right type of table
To help manage the storage costs associated with Time Travel and Fail-safe, Snowflake provides two table types, temporary and transient. Temporary and transient tables do not incur the same fees as permanent tables. Transient and temporary tables contribute to the storage charges that Snowflake bills your account until explicitly dropped. Data stored in these table types contributes to the overall storage charges Snowflake bills your account while they exist. Temporary tables are typically used for non-permanent session specific transitory data such as ETL or other session-specific data. Temporary tables only exist for the lifetime or their associated session. On session end, temporary table data is purged and unrecoverable. Temporary tables are not accessible outside the specific session that created them. Transient tables exist until explicitly dropped and are available to all users with appropriate privileges
For large, high-churn dimension tables that incur overly-excessive costs, Snowflake recommends creating these tables as transient with zero Time Travel retention and then copying these tables on a periodic basis into a permanent table. This effectively creates a full backup of these tables. Because each backup is protected by CDP, when a new backup is created, the old one can be deleted
Understanding Snowflake Stages
To support bulk loading of data into tables, Snowflake utilizes stages where the files containing the data to be loaded are stored. Snowflake supports both internal stages and external stages. Data files staged in Snowflake internal stages are not subject to the additional costs associated with Time Travel and Fail-safe, but they do incur standard data storage costs. As such, to help manage storage costs, Snowflake recommends monitoring these files and removing them from the stages once the data has been loaded and the files are no longer needed
It is also possible to use Snowflake to access data in on-premises storage devices that expose a highly compliant S3 API. With External Stages and External Tables against on-premises storage, customers can make Snowflake their self-service platform for working with data without having to worry about concurrency issues or the effort of managing compute infrastructure. Data governors can apply consistent policies to tables and monitor usage regardless of where the data is physically stored. Analysts and data scientists have a full view of all relevant data, whether it's on premises or in the cloud, including first-party or even shared, third-party data sets
Delete what you don't need
Similar to the earlier advice to "Don't do things you don't need to!", I'd suggest you don't keep data that you will never need and/or that you do not want to continuing keeping fresh. While storage is relatively cheap compared to compute, it still can add on to your bill.
Split large files to minimize processing overhead
To distribute the load across the compute resources in an active warehouse, export large files in smaller chunks using a split utility. This will allow Snowflake to divide the workload into parallel threads and load multiple files simultaneously, which will reduce the compute time of your virtual warehouse.
Use zero-copy cloning
This unique feature lets you create database, table and schema clones which use pointers to the live data and don't need additional storage.
As a result, you can save on storage costs and the time it takes to configure the cloned environment.
Note that by deleting the original table, storage fees transfer to the cloned table. Always delete both the original and cloned tables you're not using.
Conclusions
Snowflake is a great platform for Data Warehouse as a Service. It alleviates many of the more traditional DBA tasks I have had to perform on self hosted OLTP databases (SQL Server, MySQL, PostgreSQL, etc.).
But like any software platform (especially data platforms), we still need to consider continuous improvement that require commitments to monitoring and then possibly selected optimizations. Hopefully some of the suggestions detailed above will be helpful if you are using Snowflake.