
Open Source Data Tools I like

A few months ago I participated on a panel talking about something data related at a Snowflake user group. In the picture below, I am in the white button down shirt and blue jeans looking less excited than the guy in plaid shirt on the left.
Toward the end of the Q&A session, the moderator asked the panelists what open source data tools do they use. I thought it would be nice to share my answers here as some of them were new to folks in the audience. These are all tools / frameworks my teams and i have experience with implementing:

Site: https://www.getdbt.com
Tagline: dbt applies the principles of software engineering to analytics code, an approach that dramatically increases your leverage as a data analyst.
Tech: Written in python
So what problem does it solve?
It is common for data folks to need to take raw data from a myriad of sources, load into a data warehouse, and then need to:
- build new tables with aggregated data
- take snapshots of data for time series analysis.
As your data needs grow and you have more folks working on these types of tasks, you can start to see jobs with many steps daisy chaining one new aggregated table called by another. Understanding, testing, and debugging can get incredibly challenging (my teams faced this on a daily basis supporting hundreds of legacy aggregated tables/views). And it gets exponentially worse as subject matter experts leave your team/company.
This was such a pain point that my team was in the process of creating our framework to tackle these types of problems.
What is it?
dbt (data build tool) is a command line tool that enables data analysts and engineers to transform data in their warehouses more effectively.
Below is a picture of a modern data stack+pipeline - doing Extract, Load, Transform (known as ELT). dbt is handles the Transform step as shown below:
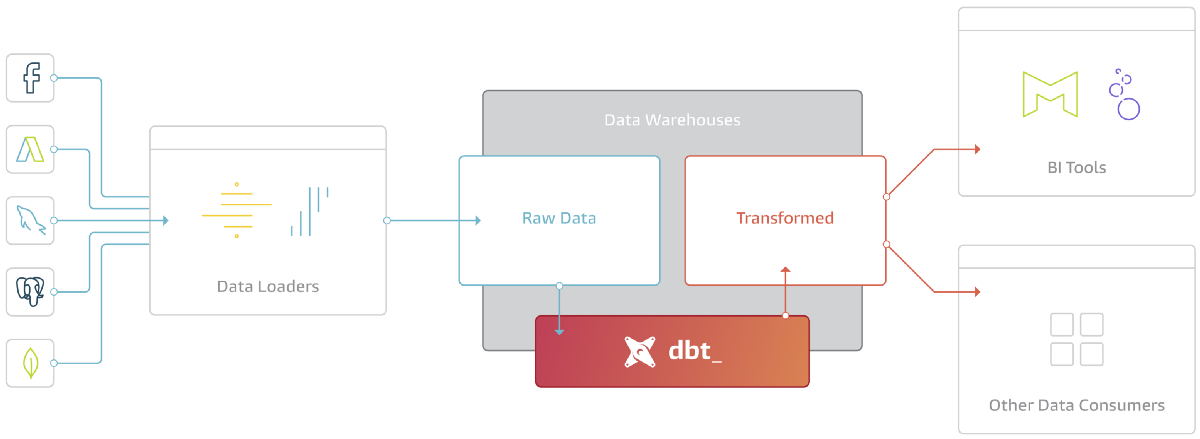
The dbt framework essentially takes sql templates (jinja files) where define tables as . So your code may

Once you run "dbt run" from the command line, the framework can figure out the order to build the aggregated tables (meaning build the tables that other downstream tables depend on). It even generates out a nice visual graphic of that dependency tree as part of the run sequence (shown below). This alone was a huge thing for us.

dbt also allows us to define "tests" - SQL statements defined to validate some cases that you care about in the data of tables in the data warehouse. This is great to run on both source data (coming from upstream systems) as well as the dbt created aggregate data. This allowed us to find+monitor for all sorts of problems/inconsistencies in data from source systems that cost us so many hours of complex troubleshooting.
I found this this excellent blog post in late 2017 and we a working proof concept within a week. It proved out many of our risk areas and it was quickly adopted by a variety of teams (you really need to know SQL to use it).
Fast forward 2+ years, dbt has added all sorts of excellent features (including their own IDE and cloud offering) and has grown significantly in adoption.

Site: https://greatexpectations.io
Tagline: Great Expectations (GE) helps data teams eliminate pipeline debt, through data testing, documentation, and profiling.
Tech: Written in python
While tests in dbt are really convenient+helpful, GE takes it to a different level. Here are some places I have used it:
- You can point GE at your existing database and it will generate out some nice documentation for you.
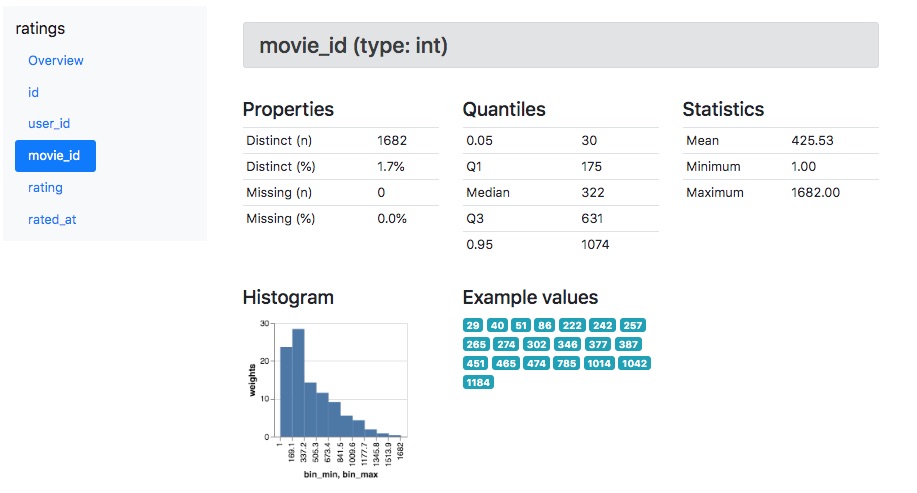
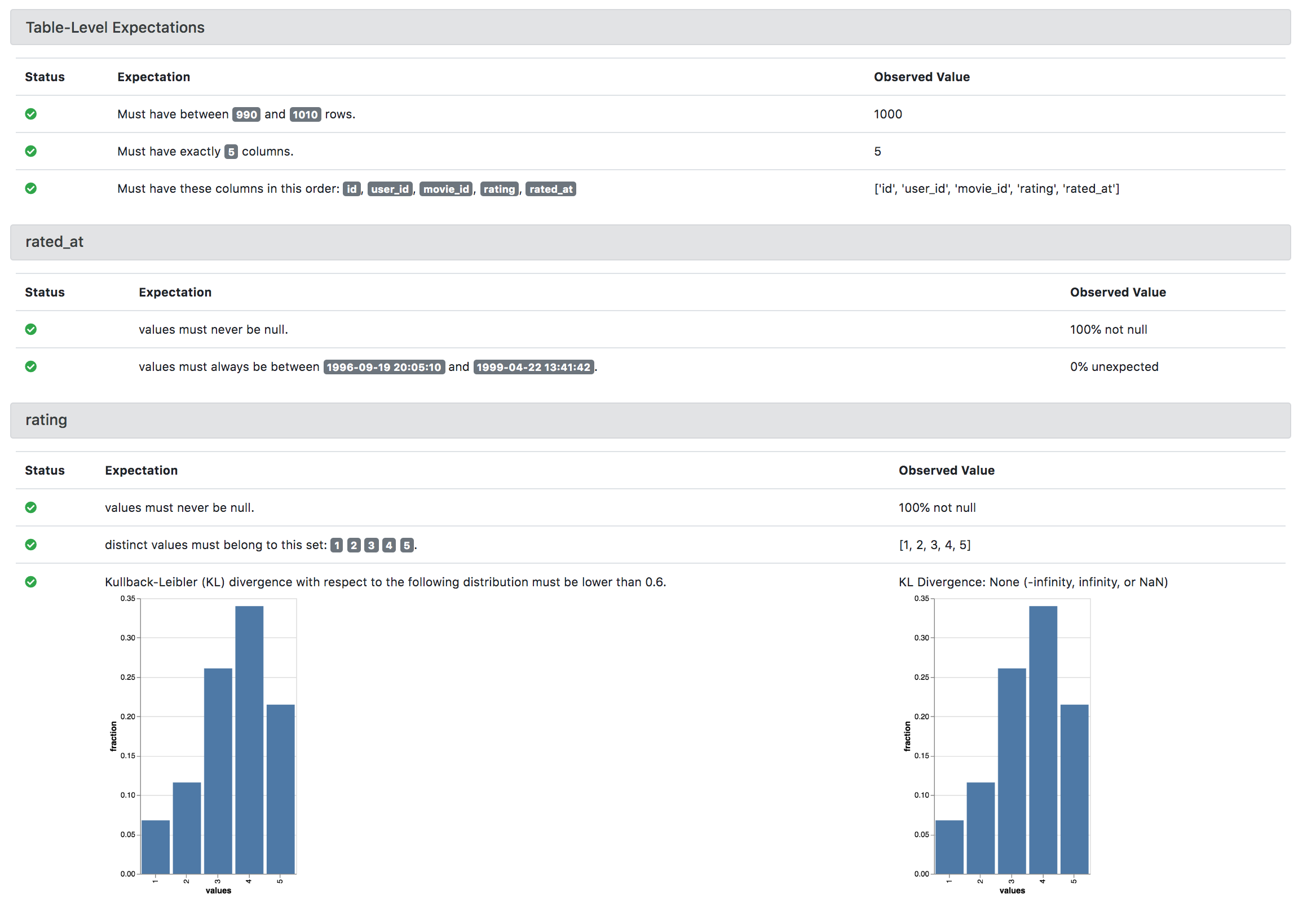
- We can define validation rules (called "expectations") that can be run against flat files or database tables. Below are some basic examples of these rules:

- I have run these validation process for these expectations from jupyter, before file uploads, as part of ETL/ELT pipelines. You can even have the GE process generate out docs like this:

Site: https://superset.incubator.apache.org
Tagline: Apache Superset (incubating) is a modern, enterprise-ready business intelligence web application.
Tech: Written in python
So what problem does it solve?
You have lots of data, GREAT! But you will probably want a way to build reports and visualizations so you can understand and share out what that data means to your business.
There are great commercial offerings out there (like Tableau and Looker), but they are usually pretty expensive and have more overhead to administer.
What is it?
I am not going to go into detail of this here, since I wrote a blog post on my experience test driving SuperSet last year:
http://jaygrossman.com/apache-superset-test-drive/

Site: https://debezium.io
Tagline: Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases.
Tech: Written in Java
I saved the most ambitious one for last.
So what problem does it solve?
It is common need for companies to want to be able to:
- Sync all data changes between source systems (like production databases) and their reporting systems (data warehouse/data lake).
- Build a real time series (without taking snapshots of tables) of all changes on key tables / data sets
What is it?
Debezium is a set of distributed services that capture row-level changes in your databases so that your applications can see and respond to those changes. Debezium records in a transaction log all row-level changes committed to each database table. Each application simply reads the transaction logs they’re interested in, and they see all of the events in the same order in which they occurred.
Change Data Capture, or CDC, is an older term for a system that monitors and captures the changes in data so that other software can respond to those changes. Data warehouses often had built-in CDC support, since data warehouses need to stay up-to-date as the data changed in the upstream OLTP databases. Debezium is essentially a modern, distributed open source change data capture platform that will eventually support monitoring a variety of database systems.
The diagram below illustrates how debezium can be used as part of a CDC solution:
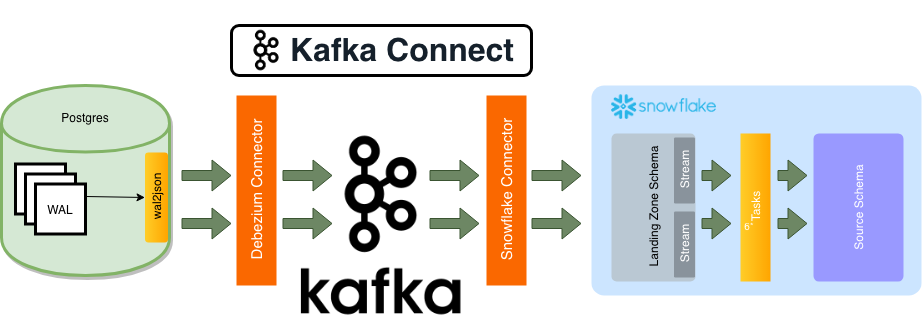
Adrian Kreuziger has written an excellent blog post that provides a high level walk you through how he set this up for Convoy. It walks through considerations for PostGres (we used it with mySQL), Kafka, Kafka Connect, and Snowflake.
In 2015, my team wrote something custom in Java to do some of what debezium does (capture change records from mySQL and write them to Kafka) to support requirements for real time time series. It was my first experience setting up Kafka and running it in production, so I learned a ton (both good and bad). Debezium (and KafkaConnect in general) were attractive because the creators seemed to have good options, it had configuration options out of the box, and we could get some community support.
Please Note:
There are some great commercial offerings in this space (FiveTran, Stitch Data, etc.) that make it super easy to set up regular data sync'ing data between data stores. You should definitely consider those offerings before building your own version of this - managing kafka yourself is non trivial. We found that most vendor SLA's may not meet the needs of organizations with real time and near real time requirements (such as running a logistics operation with hundreds of workers on a warehouse floor).