
Automating Image Processing with Python

If you have been reading this blog, you'll know I collect sports cards. It's fun to share what I have with other collectors (by posting scans on sportscollectors.net, facebook, etc.).
A few years ago I bought a Brother MFC-9130CW all in one printer/scanner that I use to do my scanning. I usually set it to scan documents in legal format so I can fit 9 cards on a scan (3 rows by 3 columns). And since I want to do this most efficiently, I generally save them as a 200dpi pdf file with multiple pages.
The requirements:
- We will have a multipage pdf, with each page containing a 3x3 grid of equal sized card images. I will use this sample file for this exercise: sample_cards_file.pdf (3.02 mb)
- We will need each image cropped to show the full card (we can have some extra space around it) and saved to it's own jpeg file. An example is show below:

- I will supply a directory path containing the outputted images. Since I will put them in my inventory database, I'll need to supply the starting number for the image names and have each subsequent image increment by one.
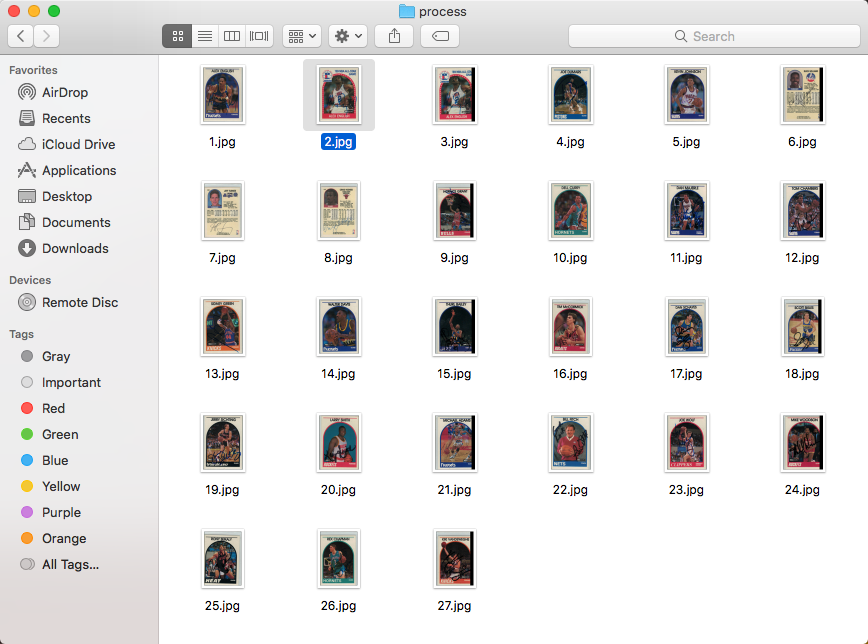
The process:
I like using Python for automating things, as it seems to have libraries for most things I want to do. So I figured it would be a good candidate for this project.
- The first thing we will want to be able to define some global variables
#paths source_file = '/tmp/sample_cards_file.pdf' out_dir = '/tmp/process/' # page setup rows = 3 cols = 3 # defines where the last run of this left off on (first item will be 1.jpg if 0) starting_count = 0 #spacing offsets top_offest = 0 left_offset = 260 bottom_offset = 0 right_offset = 0 spacer = 40 vert_spacer=0
- We will need to do is convert the each page of the pdf to a jpeg file.
Python has a library called pdf2image to do this:
pip install pdf2image pip install poppler # I used this syntax instead do of pip when running this in a jupyter notebook # conda install -c conda-forge pdf2image # conda install -c conda-forge poppler from pdf2image import convert_from_path # function that converts multipage pdf to individual # jpeg images. Function returns list of image paths. def convert_pdf_to_jpegs(pdf_path, out_dir): file_paths=[] pages = convert_from_path(pdf_path, 500) page_count = 1 for page in pages: image_path="{}temp_page_{}.jpg".format(out_dir, str(page_count)) #add to the list file_paths.append(image_path) #save converted file page.save(image_path, 'JPEG') page_count += 1 return file_paths - We will have a function that breaks up an image with our 9 cards and save each individually to a specified directory. We will need the ability to seed the first image name. The function can use the spacing offset variables
from PIL import Image def split_images_from_page(image_path, out_dir, row_count, col_count, start_number): # opens the image file Im = Image.open(image_path) # calculates height and width of image full_width = Im.width full_height = Im.height image_height = int((full_height - vert_spacer - top_offest - bottom_offset) / rows) image_width = int((full_width - spacer - left_offset - right_offset) / cols) image_count = 0 row_current=1 #iterates through rows and columns while row_current <= row_count: col_current = 1 while col_current <= col_count: # calculates the coordinates on the image to crop croppedIm = Im.crop((left_offset + ((col_current - 1) * image_width) + spacer, top_offest + ((row_current - 1) * image_height), min(left_offset + (col_current * image_width) + ((col_current - 1) * spacer), Im.width), top_offest + (row_current * image_height) + vert_spacer)) # if you wanted to resize the image to 300 width and 420 height # croppedIm = croppedIm.resize((300, 420)) # saves the image to specified directory croppedIm.save("{}/{}.jpg".format(out_dir, start_number+image_count)) col_current += 1 image_count += 1 row_current+=1 - Calling the functions:
import os page_count = 1 # convert pdf to jpeg file for each page file_paths = convert_pdf_to_jpegs(source_file, out_dir) # split each page into images for file_path in file_paths: number_start = starting_count + (page_count-1) * (rows * cols) + 1 split_images_from_page(file_path, out_dir, rows, cols, number_start) page_count += 1 # clean up delete jpeg files for each page for file_path in file_paths: os.remove(file_path)
Here is my ipython notebook with the code detailed above: