
Simulating Vertica's conditional_change_event
Lately my team has spent a bunch of time migrating our data warehouse from Vertica to Snowflake. While Snowflake has excellent support for analytic functions, Vertica has some functions that no other columnar database supports.
The conditional change event function "assigns an event window number to each row, starting from 0, and increments by 1 when the result of evaluating the argument expression on the current row differs from that on the previous row".
CONDITIONAL_CHANGE_EVENT ( expression ) OVER ( ... [ window_partition_clause ] ... window_order_clause )
An example using the conditional_change_event function
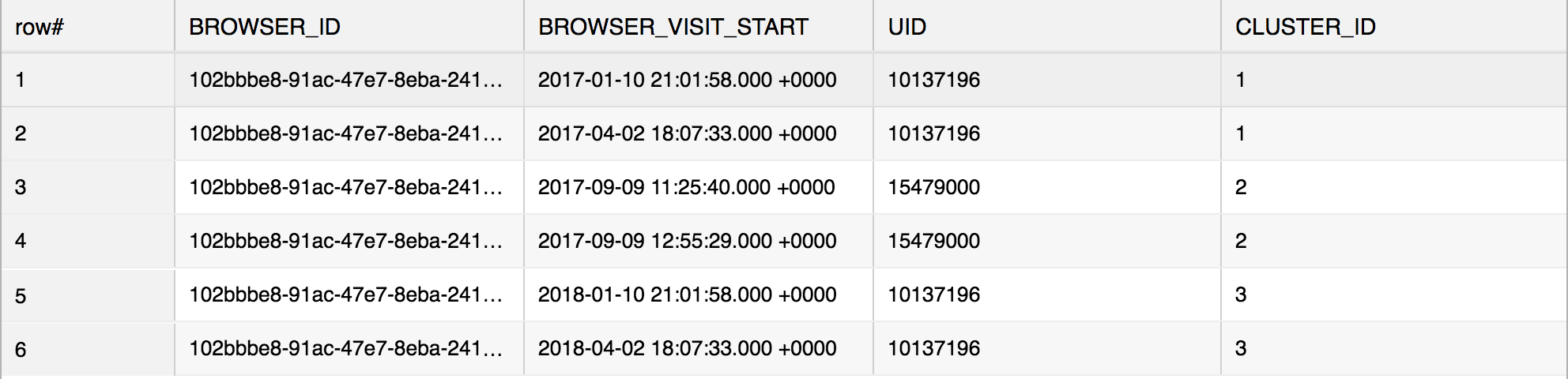
So let's say we have the following table CCE_demo:
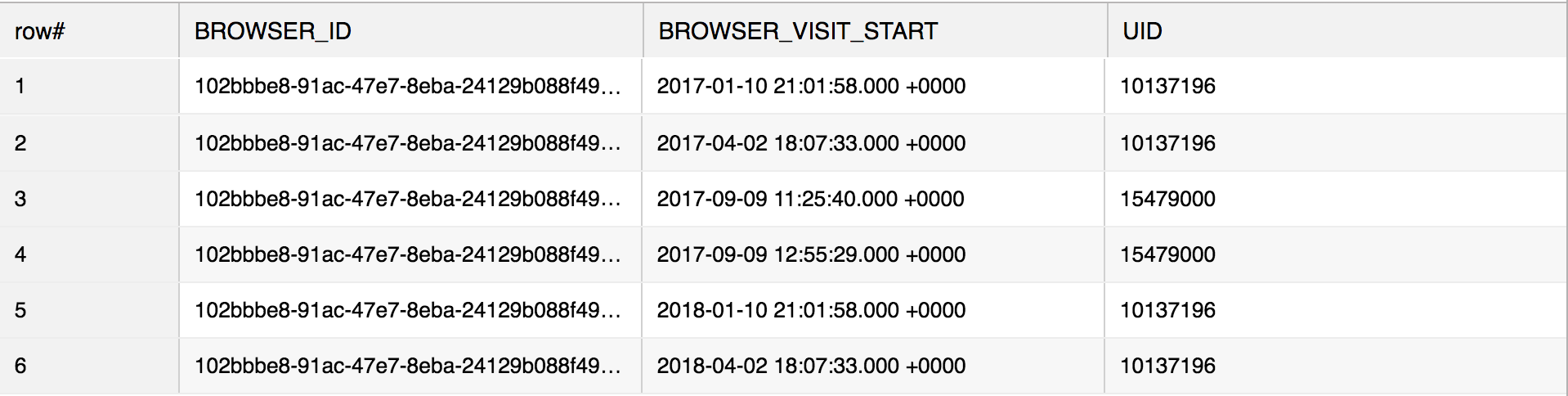
This table contains chronological visits by users using a single browser. There were 2 visits from uid=10137196, then 2 visits by uid=15479000 and then 2 more visits by uid=10137196.
We are interested in identifying each of these 3 groups of visits. A simple "GROUP BY uid" would result in 2 groups.
1
2
3
4
5
6
7
8
SELECT
browser_id
, browser_visit_start
, uid
, (conditional_change_event(uid)
over (partition by browser_id order by browser_visit_start asc) + 1)
as cluster_id
FROM CCE_Demo
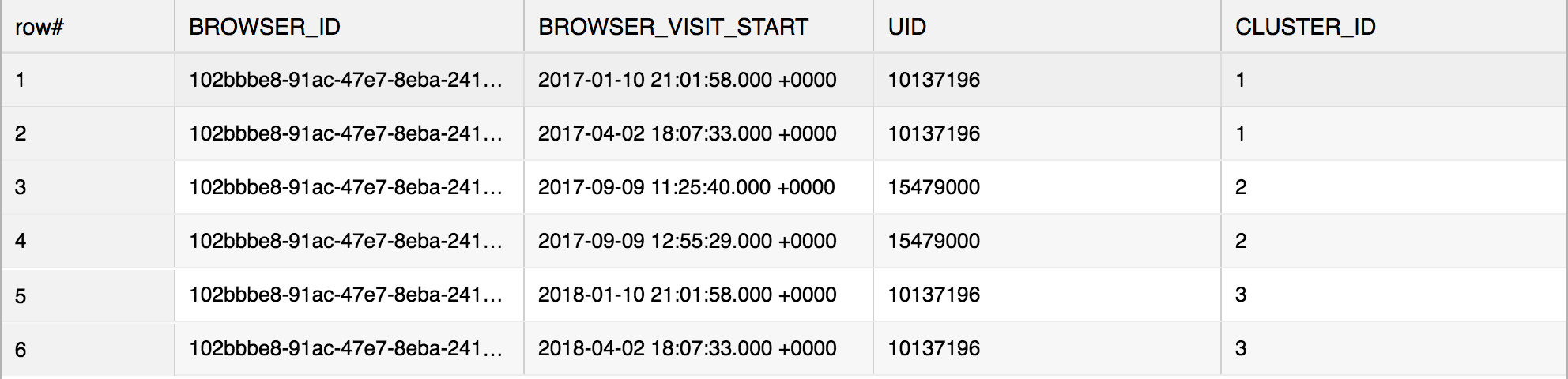
The above SQL in Vertica would result in the following:
How we can do this without conditional_change_event function
TLDR; we will use a series of window functions.
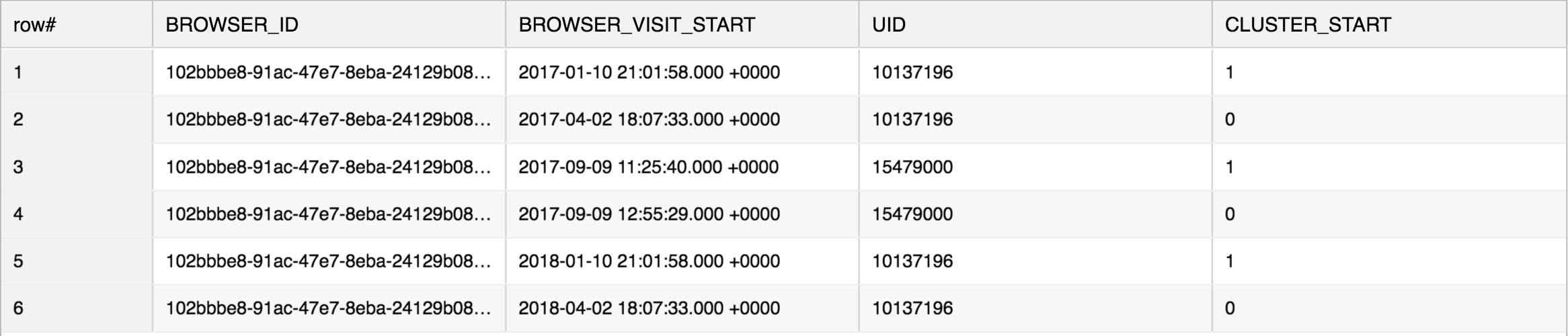
1) we can define the first element in each group of visits with cluster_start=1 (using the LAG analytic function):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-- identify the first record in each group
SELECT
browser_id
, browser_visit_start
, uid
, CASE
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) IS NULL THEN 1
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) != uid THEN 1
ELSE 0
END as cluster_start
FROM CCE_Demo
2) Identify the unique groups:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
-- identify the first record in each group
WITH a as (
SELECT
browser_id
, browser_visit_start
, uid
, CASE
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) IS NULL THEN 1
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) != uid THEN 1
ELSE 0
END as cluster_start
FROM CCE_DEMO
)
-- get the unique groups
SELECT
browser_id
, browser_visit_start
, uid
, cluster_start
, ROW_NUMBER() over (partition by browser_id
order by browser_visit_start) as cluster_id
FROM a
WHERE cluster_start=1
ORDER BY browser_id, browser_visit_start, uid

3) We can create date windows for each cluster since we know when each one starts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
-- identify the first record in each group
WITH a as (
SELECT
browser_id
, browser_visit_start
, uid
, CASE
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) IS NULL THEN 1
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) != uid THEN 1
ELSE 0
END as cluster_start
FROM CCE_Demo
),
-- get the unique groups
b as (
SELECT
browser_id
, browser_visit_start
, uid
, cluster_start
, ROW_NUMBER() over (partition by browser_id
order by browser_visit_start) as cluster_id
FROM a
WHERE cluster_start=1
ORDER BY browser_id, browser_visit_start, uid
)
-- assign end dates to the groups, set last group's end date to 2100-01-01
SELECT
browser_id
, browser_visit_start
, uid
, cluster_id
, COALESCE(
LEAD(browser_visit_start) over
(partition by browser_id order by browser_visit_start asc),
'2100-01-01') as end_date
FROM b

4) Use the date ranges (between browser_visit_start and end_date) to designate the group:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
-- identify the first record in each group
WITH a as (
SELECT
browser_id
, browser_visit_start
, uid
, CASE
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) IS NULL THEN 1
WHEN
LAG(uid) over (partition by browser_id
order by browser_visit_start asc) != uid THEN 1
ELSE 0
END as cluster_start
FROM CCE_Demo
),
-- get the unique groups
b as (
SELECT
browser_id
, browser_visit_start
, uid
, cluster_start
, ROW_NUMBER() over (partition by browser_id
order by browser_visit_start) as cluster_id
FROM a
WHERE cluster_start=1
ORDER BY browser_id, browser_visit_start, uid
),
-- assign end dates to the groups, set last group's end date to 2100-01-01
c as
(
SELECT
browser_id
, browser_visit_start
, uid
, cluster_id
, COALESCE(
LEAD(browser_visit_start) over
(partition by browser_id order by browser_visit_start asc),
'2100-01-01') as end_date
FROM b
)
-- use the window between browser_visit_start and end_date to assign the correct group to each record
SELECT
d.browser_id
, d.browser_visit_start
, d.uid
, cluster_id
FROM CCE_Demo d
LEFT OUTER JOIN c
ON d.browser_id=c.browser_id
AND d.uid=c.uid
AND d.browser_visit_start>=c.start_date
AND d.browser_visit_start<c.end_date
ORDER BY
d.browser_id, d.browser_visit_start
Other things we could have done
The real data we have in our database that this example was based off of a table with 250 million rows. So taking advantage of scalable query processing in an MPP database was desirable.
1) Build a custom user defined function (using javascript and a FOR loop).
2) Export it to a language like Python or Java and use a FOR loop.