
Modern Data Stack in a box (all Open Source)
This week I participated in a hackathon for fun with a couple of friends. There were 3 rules for each of us:
- Upgrade something you are unhappy with in a side project
- Try some new piece of tech
- Document what you did
My project
Over the past 10 or so years, I have had a lot of fun running CollectZ - Research and Arbitrage Platform for collectibles categories.
TL;DR - The platform informs what undervalued collectibles I should consider buying and when + where + at what price I should sell my inventory.
If you are trying to run arbitrage (exploiting inefficiencies between marketplaces) effectively with physical (non-liquid) assets, it is rather important to be able to have a pretty diverse data set and be able do analysis + reporting + run models across a variety of features.
My problem
As I went along building out my platform, I had data sitting in different diverse repositories and in many formats. Some of the exploration and reporting tools I cobbled together over the years suffered because they were:
- fragile to keep running (things broke unexpectedly)
- hard to troubleshoot for data lineage issues
- performing slowly with more advanced queries (based off relational databases and file stores)
- labor intensive to extend
- lacking the general features I wanted
The tech debt became more than just noticeable, as it was impacting the effectiveness of the platform and more importantly effectiveness of my trades.
Requirements for something better
Before I go about building anything, it is a really good idea to write down some requirements.
When thinking about my reporting and data exploration needs for CollectZ, I had some requirements:
- I want a fully open source (free) stack that I can configure to run locally on my laptop and could be run in a cloud provider (likely AWS).
- I want to use dbt to build my models
- I want relatively a fast centralized data store (preferably columnar based)
- I want a way to keep the reporting sync'd regularly from production / source systems
- I want an off the shelf tool for self service data exploration and BI
The Data
For this exercise, I am using a subsection of recent transaction and valuation data for Sports Cards category.
I have exported data from 7 tables into .csv files and posted them to S3. Below is a relationship diagram source data model we will be working with:

| Table | Description | Record Count |
| Item | Reference information about a sports card in our catalog | 116,459 |
| ItemValue | Weekly calculated values for each item in different conditions | 5,746,066 |
| CardSet | The sport, year and name for each set associated with the card | 691 |
| Sport | The sport associated with the card set | 4 |
| ItemTransaction | Recent sales for selected items | 3,175,362 |
| ActiveItem | Items available for sale | 4,489,085 |
| Source | Sources of data for ItemTransaction and ActiveItem | 12 |
|
Please Note: I am not able to share actual Collectz data on my blog and how we get this (let's assume there are lots of fun data engineering pipelines at work here). |
Solution Architecture
I have run data teams that build out data products for my day job, so I knew I could streamline and modernize on some best practice tooling.
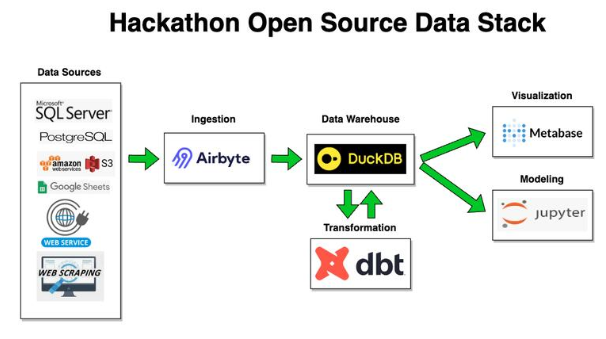
The components of my stack:
- DuckDB - our local data warehouse
- Airbyte - for populating data into DuckDB
- dbt - for building models for analysis
- Metabase - BI tool
- Jupyter - for ad hoc analysis via Notebooks
DuckDB
I have a good amount of experience with commercial cloud data warehouses (Snowflake, BigQuery, DataBricks). While they are great products, they are all pretty expensive and I don't have budget for a personal project like CollectZ. I wanted something free + open source that I could run locally for development and later in AWS for production.
My first thought was to go with Postgres, but I wasn't overly excited to manage a relational database (index, keys, etc.) and I like columnar databases for analytics. I also thought about Druid, but that would involve some overhead to set up and surprisingly doesn't yet have dbt integration.
My friend Rob told me about how DuckDB offered much of the functionality I liked in Snowflake, but it was super easy to manage and would run locally on my laptop.
DuckDB is an in-process SQL OLAP database management system. AND I really like the idea of their tagline:
All the benefits of a database, none of the hassle.
After playing around with it, I found the main points and features of DuckDB?
- Simple, clean install, with very little overhead.
- Feature-rich with SQL, plus CSV and Parquet support.
- In-memory option, high-speed, parallel processing.
- Open-source.
DuckDB isn’t meant to replace MySQL, Postgres, and the rest of those relational databases. In fact, they tell you DuckDB is very BAD at “High-volume transactional use cases,” and “Writing to a single database from multiple concurrent processes.”
This 10 minute Youtube video from Ryan Boyd does a good job with more background on DuckDB:
Installation Instructions:
Reference from https://duckdb.org/docs/installation/
- brew install duckdb
Airbyte
I have implemented FiveTran at 2 of my day jobs (ElysiumHealth and Luma), and it is a very easy to configure tool to set up pipelines to sync data from various sources into a data warehouse. Overall it works well if you do not have low latency requirements (it is great for hourly syncs), but it is volume based and can be quite expensive once you go past syncing 500,000 records in a month on their new free tier offering.
For this project, I wanted to try the closest Open Source equivalent I could find - Airbyte.
|
Please Note: The latest version or Airbyte 0.443, only supports DuckDB 0.6.1 (version 39). All the other tools in this post I am configuring are using DuckDB 0.8.0 (which launched within the past month), so I would not be able to use Airbyte in this full stack until its DuckDB version support is aligns with Metabase and dbt. Airbyte is a valuable tool for syncing data (I also tried it syncing to Postgres) and I feel that is worthwhile to share my learnings of how I would/will use it. |
Installation Instructions
Reference from https://docs.airbyte.com/quickstart/deploy-airbyte/
- Install Docker on your workstation (see instructions). Make sure you're on the latest version of docker-compose.
- Run the following commands in your terminal:
git clone https://github.com/airbytehq/airbyte.git
cd airbyte
./run-ab-platform.sh - Once you see an Airbyte banner, the UI is ready to go at http://localhost:8000
By default, to login you can use: username=airbyte and password=password
When I opened up Docker Desktop, you can see airbyte has 12 dockers it has running:
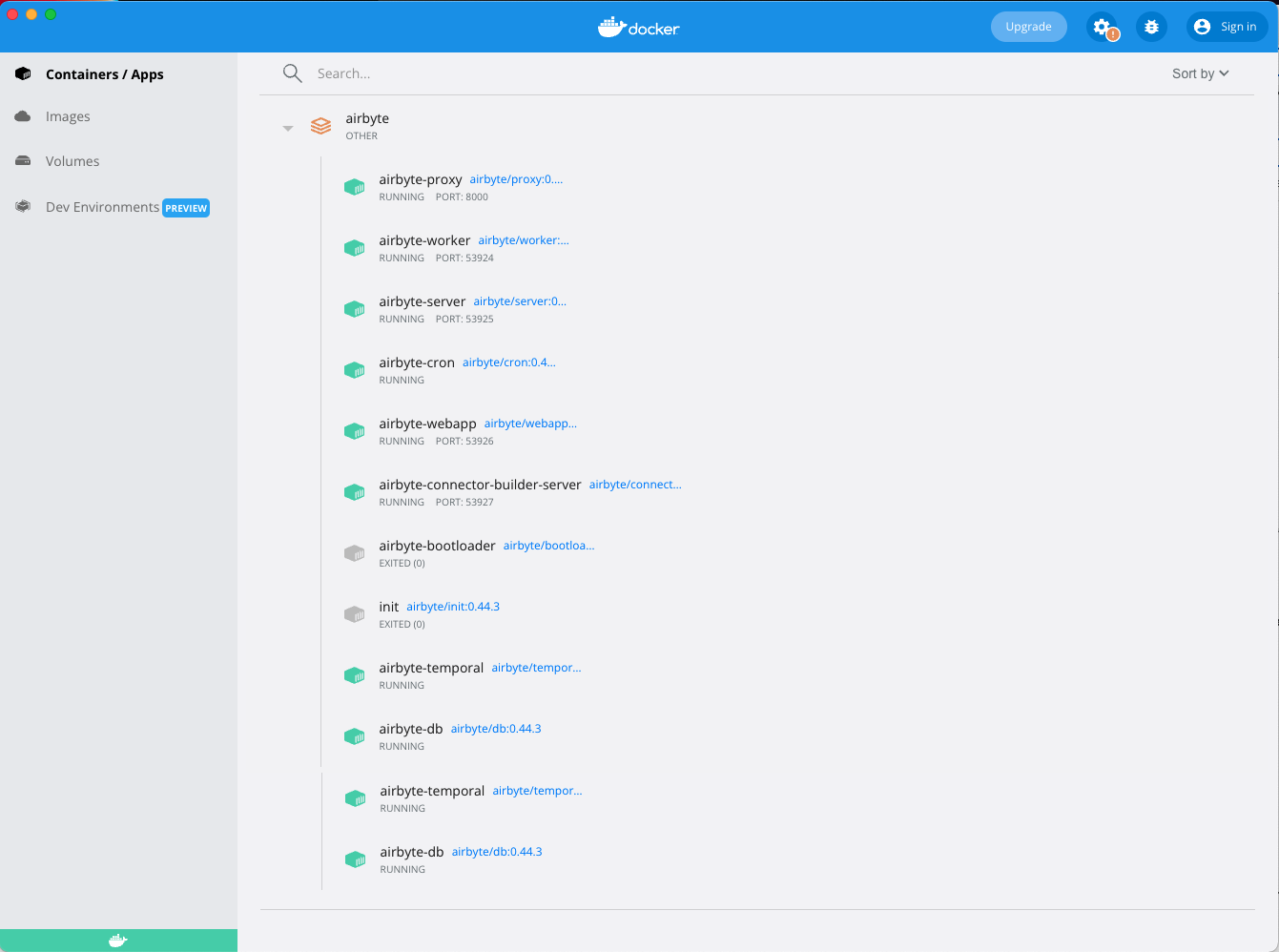
Configuring a Pipeline in Airbyte
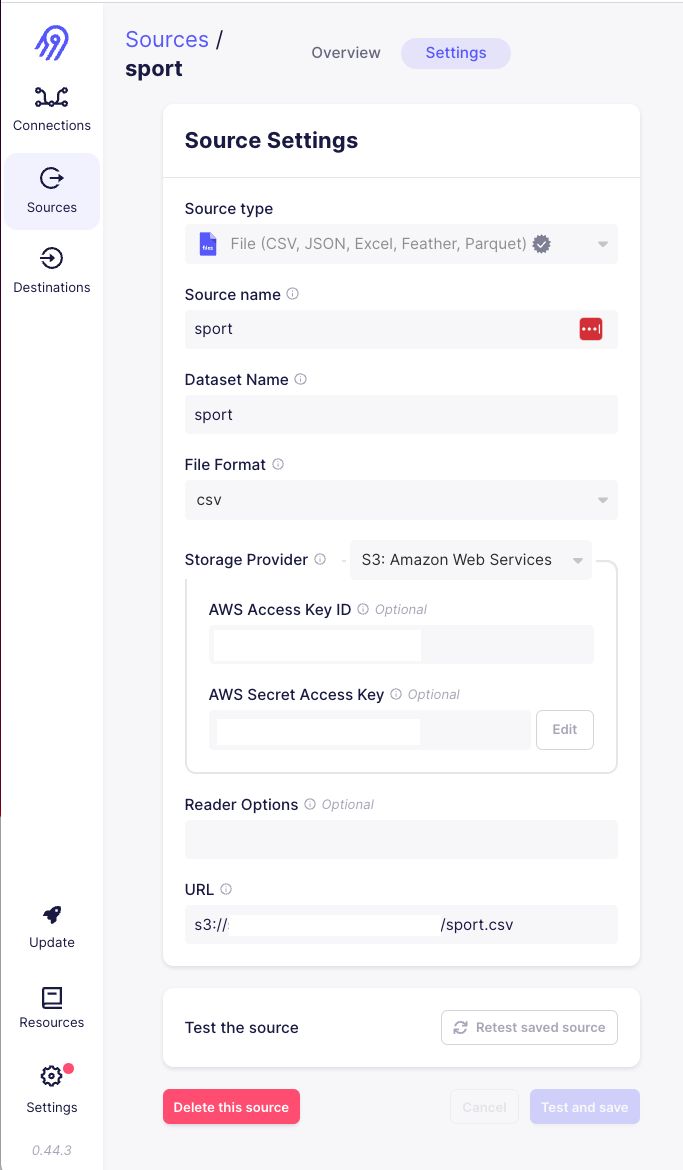
1) The first step is to set up a Source. In this case I am setting up a "File" source that can read from sport.csv in my S3 bucket. I will need to provide my AWS creds as shown below:
2) Next we will need to set up a destination where we can write the data. This link explains how to update the .env file so that a local directory on my machine will be mounted within the airbyte-server docker image.
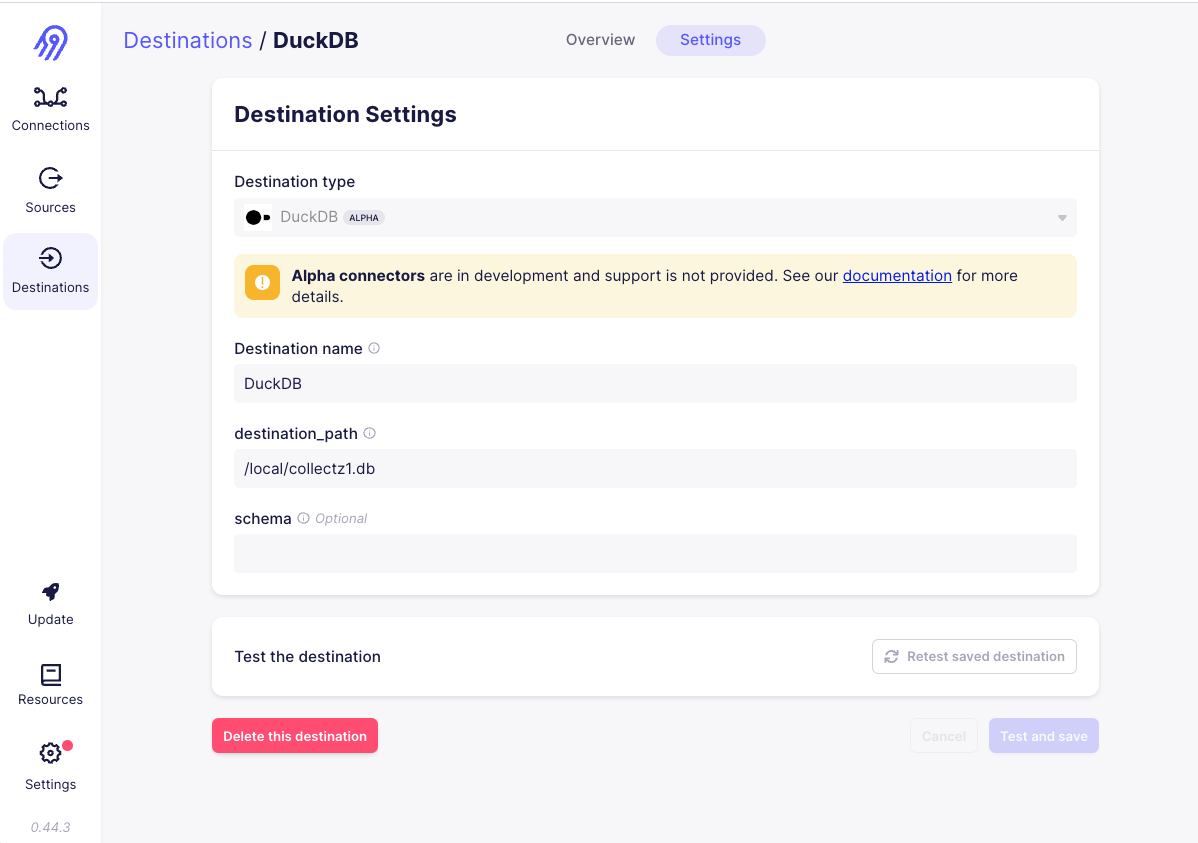
3) We will need to configure a connection that will schedule running syncs from our source to our destination:
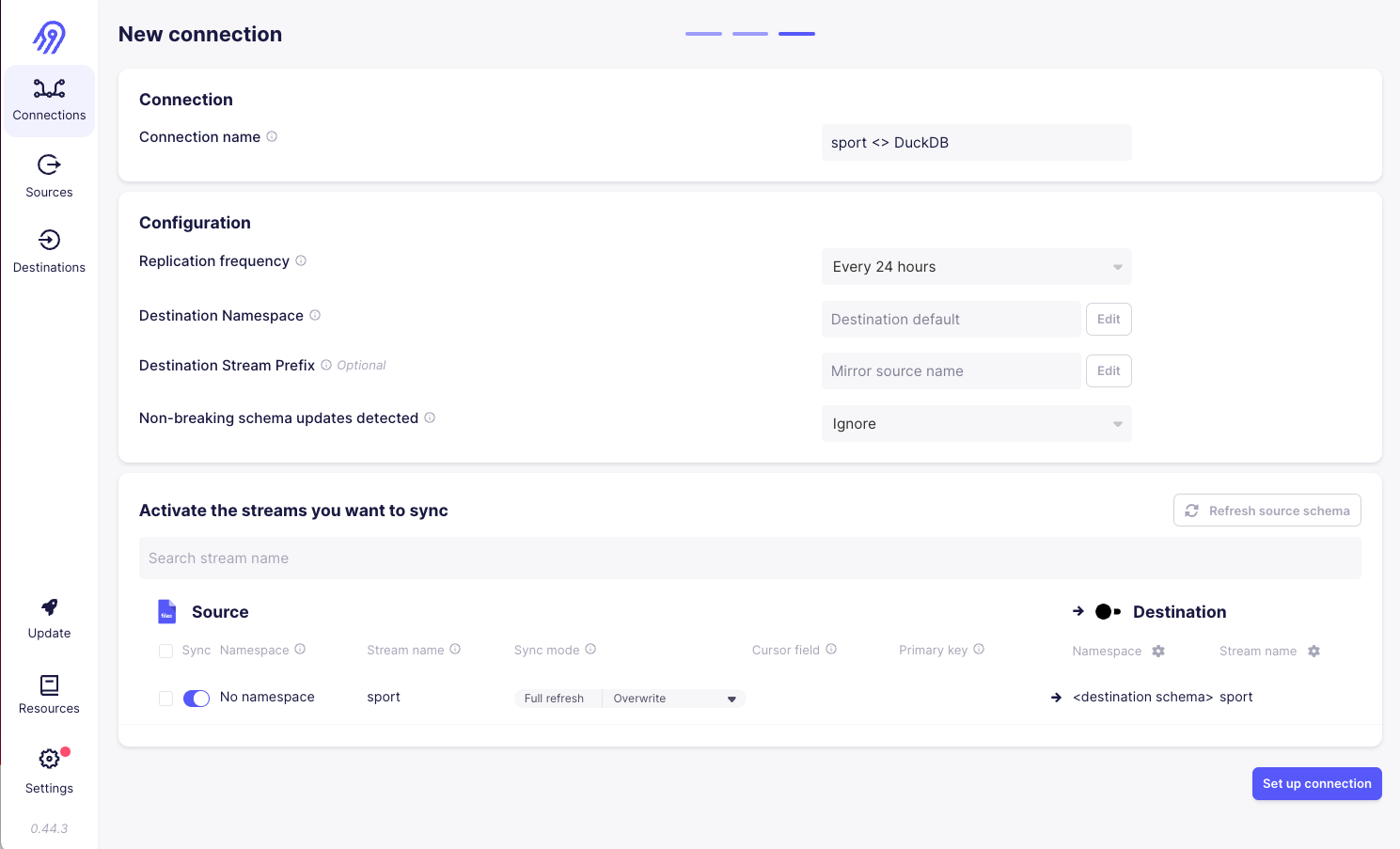
4) We see the result of the connection syncing data to my destination:
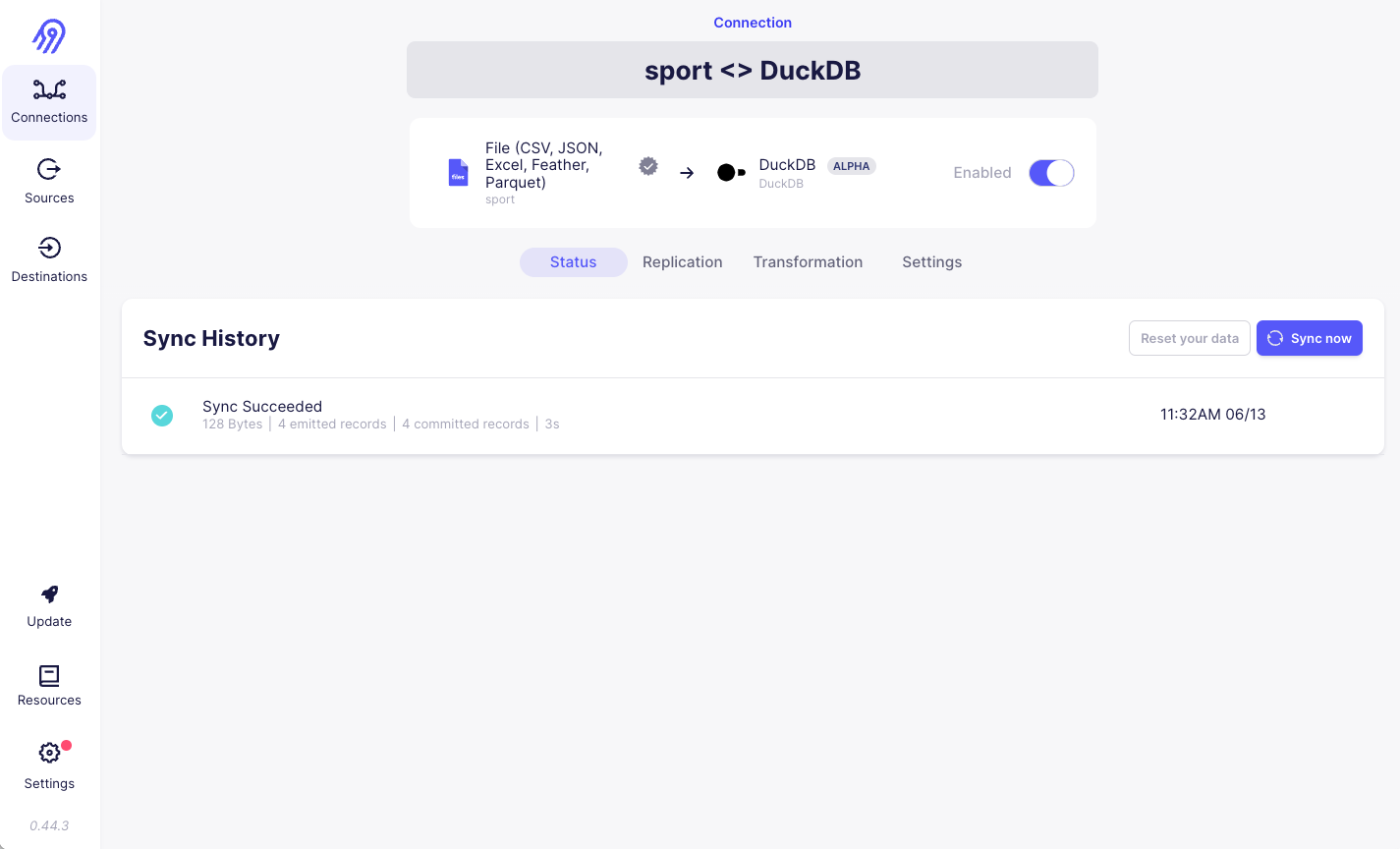
5) I checked the DuckDB database and saw the following data synced over:
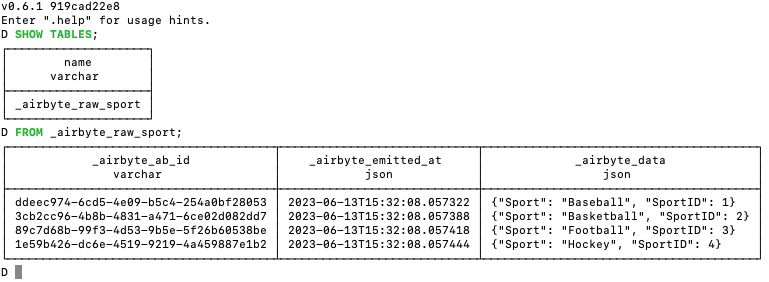
The _airbyte_data column in the screenshot above contains json representing the data in the csv file. This would need to be transformed into a relational format for reporting via a BI tool (such as metabase).
dbt support for DuckDB
dbt is a popular tool for allowing developers and analysts to create data models in SQL (and now Python), managing graph dependencies and supporting tests. I have been a user of dbt since 2017 when my team at Rent the Runway first starting use it to standardize large parts of our pipelines.
Installation + Set Up Instructions:
Reference from https://github.com/jwills/dbt-duckdb:
1) Install dbt and dbt-duckdb:
1
2
pip3 install dbt-core
pip3 install dbt-duckdb
2) Configure the ~/.dbt/profile.yml file with the following:
1
2
3
4
5
6
7
collectz:
target: dev
outputs:
dev:
type: duckdb
path: /path_to_file/collectz.db
threads: 4
3) Create a new directory and create new dbt project:
1
2
3
mkdir dbt
cd dbt
dbt init
4) I entered the name for your project collectz when prompted
Building models in dbt
This post assumes you have working knowledge of how dbt works. If you do not, their quick start is helpful.
Since I could not use Airbyte due to version incompatibilities mentioned above, I made simple models that created VIEWS on top of local copies of our 7.csv files.
Example is _raw_active_item.sql (it uses the read_csv_auto function to read in a csv) as shown below:
1
FROM read_csv_auto('/path_to _data_file/Active_Item.csv')
|
Please Note: I tried to use dbt seed which would make the larger datasets persisted as tables, but it was pretty inefficient to copy over millions of rows when DuckDB is designed to efficiently process data in files at request time. I found the read_csv_auto() function performed well on data sets with 8M+ rows. |
Now that I have "raw" tables, I created SQL files that would be my BI reporting schema containing the appropriate transformations and aggregations.
Metabase
I have used a bunch of different BI / Dashboard tools over the years. I feel like Looker is probably the best of the commercial tools, but set up is time consuming and it has become really expensive. Metabase is an open source alternative that I have found really easy to set up, easy to use, and has some of the advanced features I would want.
I found Maz's 6 minute Demo video posted below walks you through the basics from an analyst perspective doing some data exploration and then incorporating it into dashboards:
Installation Instructions:
- install java - I used this link to install Eclispe Temurin:
https://www.metabase.com/docs/latest/installation-and-operation/running-the-metabase-jar-file#:~:text=of%20JRE%20from-,Eclipse%20Temurin,-with%20HotSpot%20JVM
% java --version
openjdk 17.0.7 2023-04-18
OpenJDK Runtime Environment Temurin-17.0.7+7 (build 17.0.7+7)
OpenJDK 64-Bit Server VM Temurin-17.0.7+7 (build 17.0.7+7, mixed mode)
- Download the JAR file for Metabase OSS
- Download the DuckDB driver for metabase
- run the following commands from command line to create the metabase directory and move the jar files:
mkdir ~/metabase
mv ~/Downloads/metabase.jar ~/metabase
cd ~/metabase
mv ~/Downloads/duckdb.metabase-driver.jar ~/metabase/plugins
- Run the metabase jar file with the following commands:
cd ~/metabase
java -jar metabase.jar - got to http://localhost:3000 in your browser
|
Please Note: To productionize metabase, we will want to review this page with instructions how to: 1. run metabase with a postgres as the data store instead of using the default h2 file. 2.run the java process as a service using systemd< |
Data Configuration in Metabase:
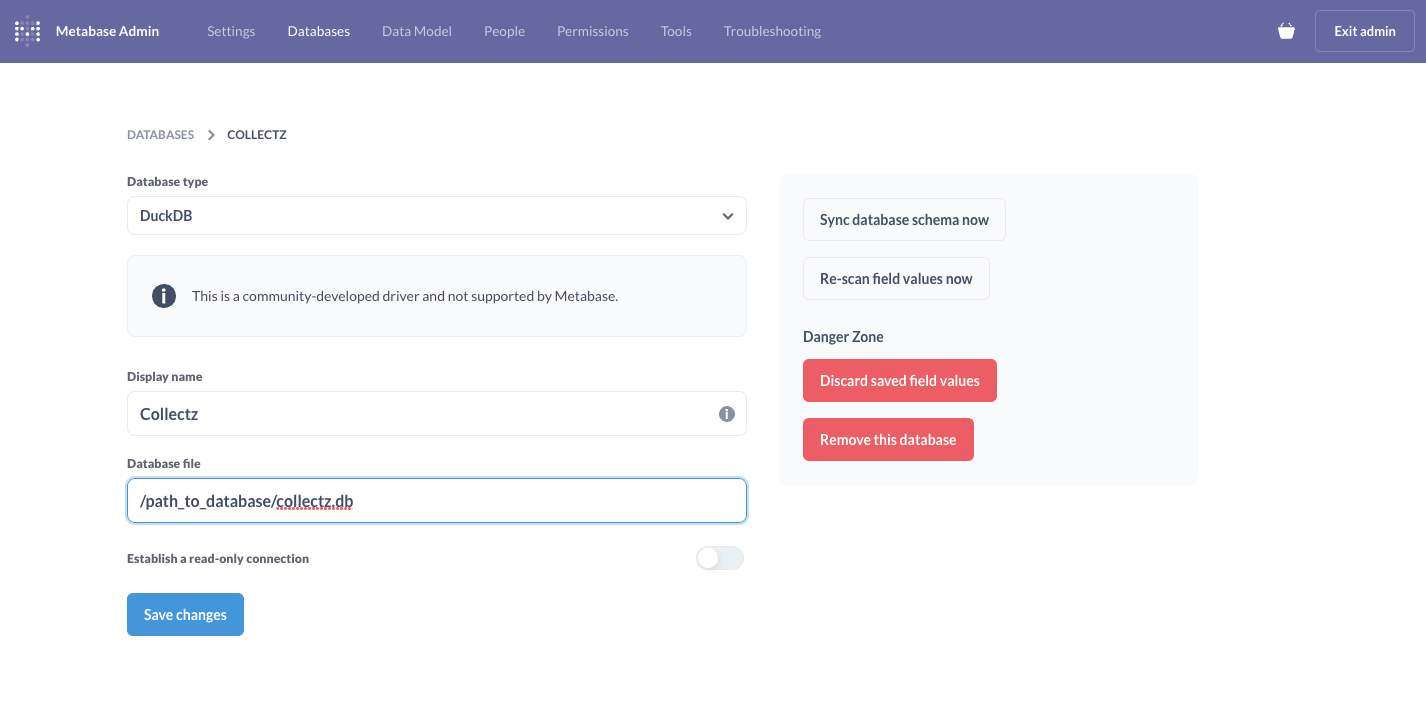
Once you log into Metabase's Admin section, you set up a connection to register your DuckDB database as shown below:
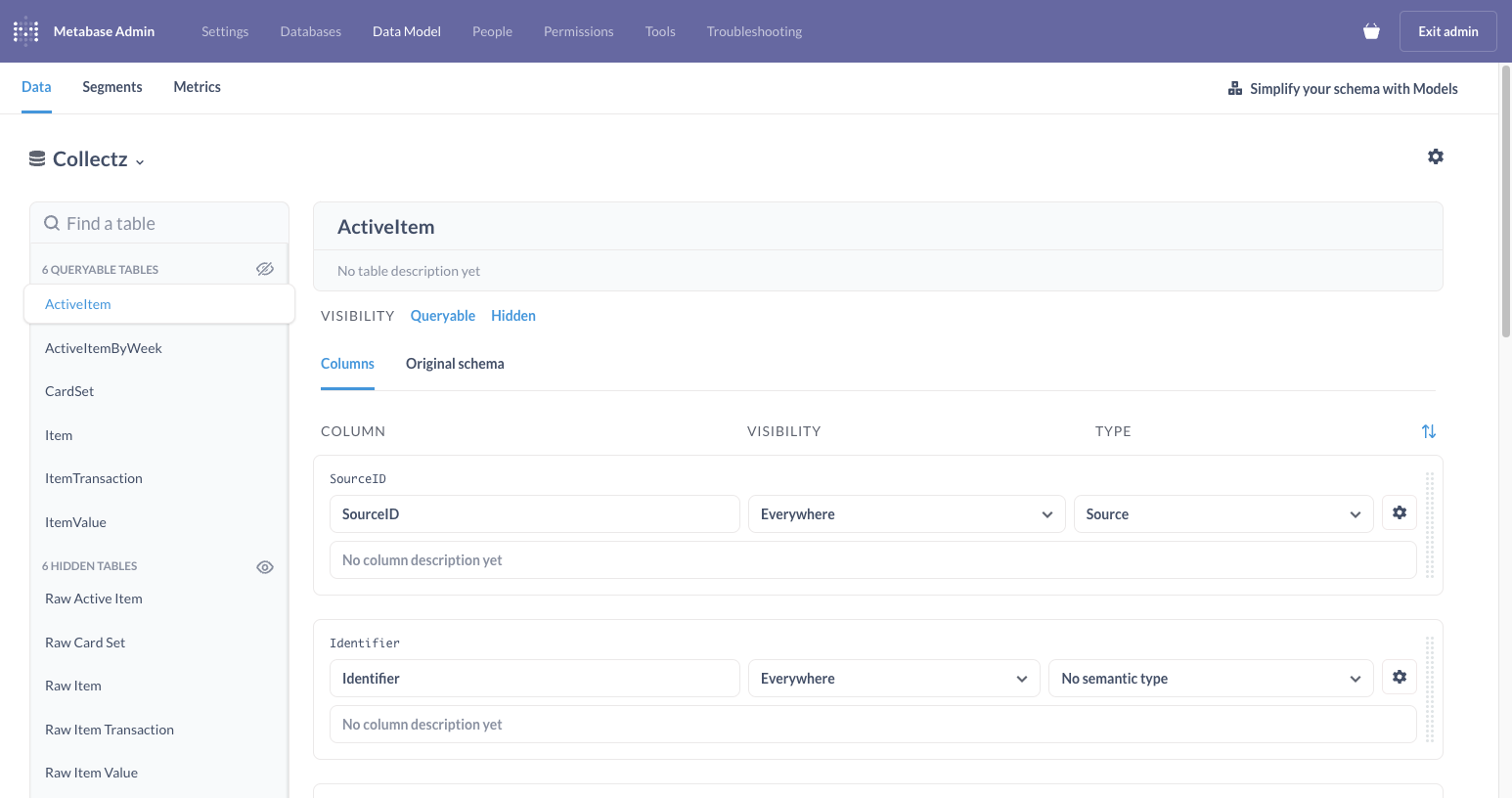
Under the Data Model area, you can define elements of your data model from any registered databases shown below. Here you can set which tables are visible and how tables join together (similar to primary-foreign keys).
The Deliverable
So I made some widgets and dashboards that make it easy enough for me to explore my data, quickly see some overviews of products with dashboards, and troubleshoot issues.
Data Exploration Example - Finding undervalued items:
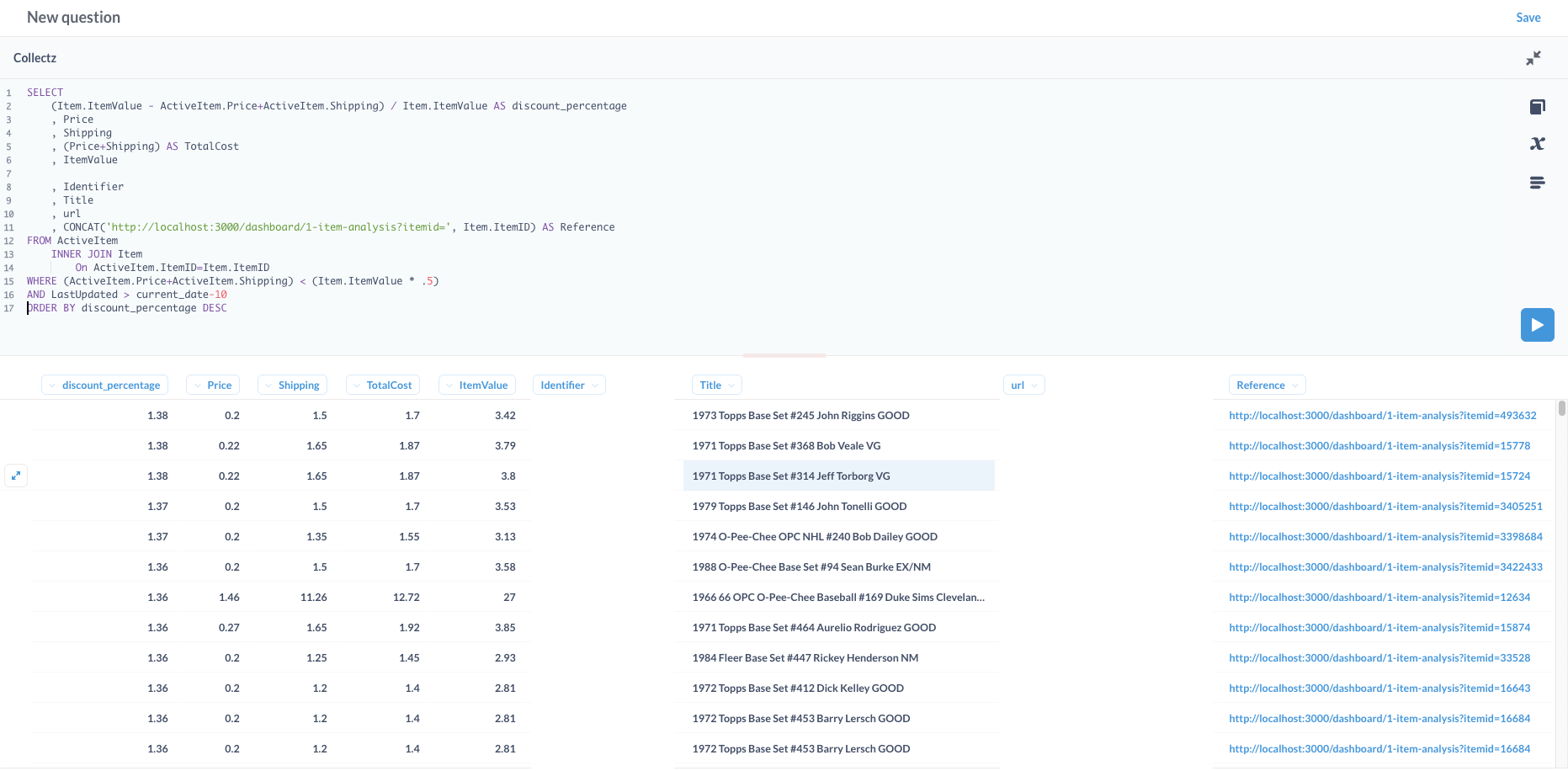
Since DuckDb doesn't have a nice web based SQLRunner like Snowflake or BigQuery, Metabase made it really easy for me to write a SQL query joining across tables with minimal aggregation + filtering to visualize results.
It took me about 2 minutes to write the query below that returns underpriced items:
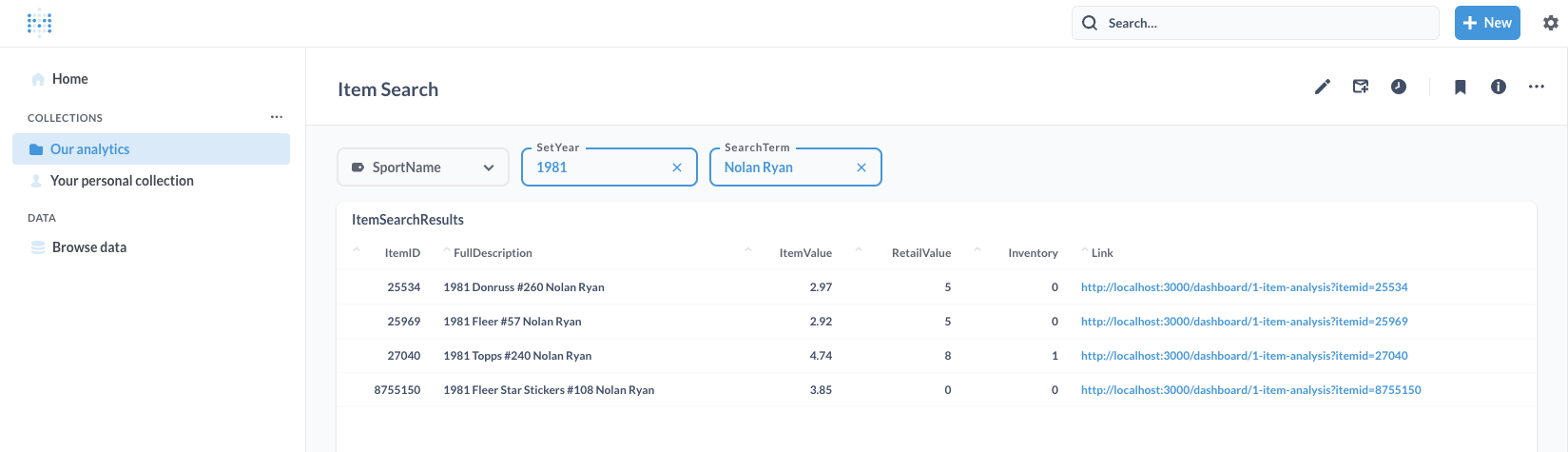
Item Search and Dashboard:
I was able to make a search screen where I can search by the year, sport and wildcard on the card's Description. Below I am searching for cards of Nolan Ryan from 1981 (the links take me to card details report):
The card details page below shows me:
- Details about the card
- If I have it in my inventory, where I am selling it, the condition and the price
- Time Series of Values (for graded and ungraded categories)
- Time Series of Volumes of sales with pricing
- Time Series of Volume of the item available (buy it now format)
- Where the item is available and for how much

Thoughts
For me, this hackathon was a great success.
- Metabase had made it easy to more effectively operationalize parts of this business with enhanced reporting and alerting.
- I now have a much easier way to answer my ad hoc and research questions quickly.
- I had the opportunity to play with a great new technology - DuckDB. And I got to integrate it with other products I like (dbt, metabase, airbyte).
- This blog post does a decent job of documenting the problem, solution approach and some implementation details + learnings.
Other Learnings / Observations:
- It is so much easier to manage running BI reporting off a columnar database vs. a relational database. DuckDB is pretty amazing for side projects if you can deal with the constraints.
- I would consider adding in an orchestration layer with Dagster. I like the idea of having ingestion, transformation and stopping/starting services controlled by a consistent and testable process.
- For ingestion, I also considered using the Singer/Meltano target-duckdb project.
- I also played with Rill Data. It is very cool for analyzing the structure of data files (csv, parquet, etc), but it can not read from DuckDB.
Inspiration from: