
Identifying Sports Cards with Image Similarity Search

I have been collecting sports cards for over 40 years and have amassed a pretty big collection. A while back I built Collectz to help me manage my collection and use data to find arbitrage opportunities in the collectibles market. A foundational component is a large catalog of cards with images — and once you have images, you can start doing interesting things with them.
One thing that comes up constantly when sorting through boxes of cards is the question: what card am I actually looking at? If you have a card in your hand and want to look it up, you typically need to know the player, year, brand, and card number. Sometimes that's easy. But for newer or unfamiliar sets, it can be a real pain to figure out.
I have seen other sites and apps offer the ability to take a photo of a card and have it identified. Ximilar.com and Cardsight.ai offer paid commercial APIs for this. I thought it would be cool to build something like that myself using modern AI tools.
The Challenge:
Given a photo of a sports card, I want to identify the card by finding the most visually similar cards in a catalog of 16.4 million cards.
My Solution: Visual Similarity Search Pipeline
A traditional approach to this problem (that I tried in the past) involves training an image classification model or an object detection pipeline. This includes labeling thousands of cards, training a model to recognize specific sets or players, and retraining whenever new cards are added to the catalog. That's a LOT of up front and ongoing work.
I thought using vector embeddings could be a cool alternative. Instead of training a classifier, you just run every card image through a pre-trained vision model to get a numerical representation (an embedding) of what the card looks like. Then to identify a new card, you embed it the same way and find the closest matches in your catalog. No custom training required — and when new cards are added, you just embed them and they're immediately searchable.
TLDR — I built a pipeline that takes a photo of a card, converts it into a vector embedding using a vision model, then searches a Facebook AI Similarity Search (FAISS) index of 3.4 million pre-computed card image embeddings to find the closest matches. The whole thing runs locally on my M1 MacBook.
Here is the high-level architecture:
The key components:
| Component | Role |
|---|---|
| SigLIP (ViT-B-16-SigLIP) | Vision model that converts card images into 768-dimensional vector embeddings |
| FAISS (IVF Flat, Inner Product) | Facebook's library for fast approximate nearest neighbor search across millions of vectors |
| DuckDB | Stores the card catalog metadata (16.4M cards) and was used during the embedding process |
The Data
The foundation of this project is the card catalog I had already built for Collectz. The collectz.duckdb database contains a card_catalog table with 16.4 million cards. Each card record includes metadata like player name, set name, year, card number, and a path to a stock image.
Of those 16.4M cards, about 3.45 million have real stock images (not just default placeholders). Those are the ones I could embed and search against.
Embedding 3.4 Million Card Images
The first major step was generating a vector embedding for every card image in the catalog. This involved downloading each image from S3, running it through the SigLIP vision model, and storing the resulting 768-dimensional vector.
This process took about 5 days of cumulative runtime on my M1 MacBook, with frequent breaks to let the machine cool down. Thermal throttling was a real issue — sustained embedding would drop from ~15 cards/sec down to ~2 cards/sec as the laptop heated up.
Optimizations I applied along the way:
- Parallel downloads (ThreadPoolExecutor) — gave me a ~10x speedup over downloading images one at a time
- Producer-consumer pipeline — downloads happen in a background thread while the GPU processes the previous batch, overlapping I/O and compute
- Bulk DB writes — single
UPDATE FROMvia temp table instead of individual UPDATEs per row - Larger batch sizes — bumped from 64 to 128 images per GPU batch
- Prefetch queue — up to 3 batches downloaded ahead so the GPU is never waiting on the network
Final sustained rate: ~15 cards/sec (bottlenecked by MPS GPU encoding on the M1 chip).
For error handling, transient failures (connection timeouts) were simply retried by re-running the script. Permanent errors (404s from S3 — about 3,500 cards) were logged and skipped. Final coverage: 3,429,911 cards embedded — 99.5% of those with images.
Making Search Fast with FAISS
My first attempt at search used DuckDB's built-in list_cosine_similarity() function to brute-force compare the query embedding against all 3.4M stored embeddings. It worked, but each query took 5-10 seconds — not great.
The fix was to build a FAISS index. FAISS is Facebook's library for efficient similarity search over large collections of vectors. I built an IVF (Inverted File) index with 1,852 clusters and inner product similarity.
The result:
- Index file: ~10GB on disk (
faiss.index) - Search time: <1ms (was 5-10 seconds with DuckDB brute force)
Memory-mapped loading:
Loading the 10GB FAISS index into memory was slow (~21 seconds at startup). Switching to faiss.IO_FLAG_MMAP (memory-mapped I/O) fixed this — the index gets loaded on-demand from disk, bringing total query time down from ~21s to ~7.7s.
Simplifying the Pipeline
An earlier version of the pipeline used Ollama running Gemma3 (a 4B parameter vision-language model) for two extra stages: identifying the player name from the card image, and then confirming whether the top FAISS matches were correct. This added ~12-14 seconds per query and didn't meaningfully improve accuracy for the common case, so I removed those stages from the default pipeline.
The final pipeline is straightforward:
- Embed the query image with SigLIP
- Search the FAISS index for nearest neighbors
- Look up card metadata in DuckDB
- Return JSON results with similarity scores
Performance
| Catalog size | 16,465,615 cards |
| Cards embedded | 3,429,911 (99.5% of those with images) |
| Query time | ~7.7 seconds |
| Embedding model | SigLIP ViT-B-16 (768-dim) |
| Index type | FAISS IVFFlat, 1,852 clusters |
The ~7.7 second query time breaks down as:
- ~5-6s: Loading the SigLIP model (cold start)
- ~1-2s: Embedding the query image on MPS
- <1ms: FAISS search
- <100ms: DuckDB metadata lookup
The model cold start dominates. This could be eliminated by running a persistent server (like FastAPI) that keeps the model loaded in memory.
Usage and Results
To show how this works in practice, I scanned a 1977 Topps Harold Carmichael card in an album page from my collection:

Running it through card_search.py with the --top-k flag set to return the top 5 matches:
1
python card_search.py 1774277243-1_4.png --top-k 5
Returns the top 5 matches — the correct card comes back first with a 0.919 similarity score, followed by other Harold Carmichael cards from neighboring years:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
[
{
"player": "Harold Carmichael",
"set_name": "1977 Topps",
"card_no": "144",
"team": "Philadelphia Eagles",
"similarity": 0.919
},
{
"player": "Harold Carmichael",
"set_name": "1976 Topps",
"card_no": "425",
"similarity": 0.8678
},
{
"player": "Harold Carmichael",
"set_name": "1978 Topps",
"card_no": "379",
"similarity": 0.8675
},
{
"player": "Harold Carmichael",
"set_name": "1983 Topps",
"card_no": "137",
"similarity": 0.8413
},
{
"player": "Harold Carmichael",
"set_name": "1981 Topps",
"card_no": "35",
"similarity": 0.8317
}
]
The top match nails it — 1977 Topps #144. The remaining results are all Harold Carmichael cards from other years, which makes sense since those cards share similar visual elements (Eagles uniform, similar photography style). The similarity scores drop off gradually, showing the model can distinguish between the exact card and visually related ones.
Integrating into Collectz
I integrated the card identifier into Collectz under the Tools menu. You can drag and drop one or more card images into the upload area or click to choose files from your computer:
The Card Identifier tool on Collectz with drag-and-drop file upload
As an example, I uploaded that same photo of a 1977 Topps Harold Carmichael card from above. The tool identifies the card and returns the top matches with similarity scores:
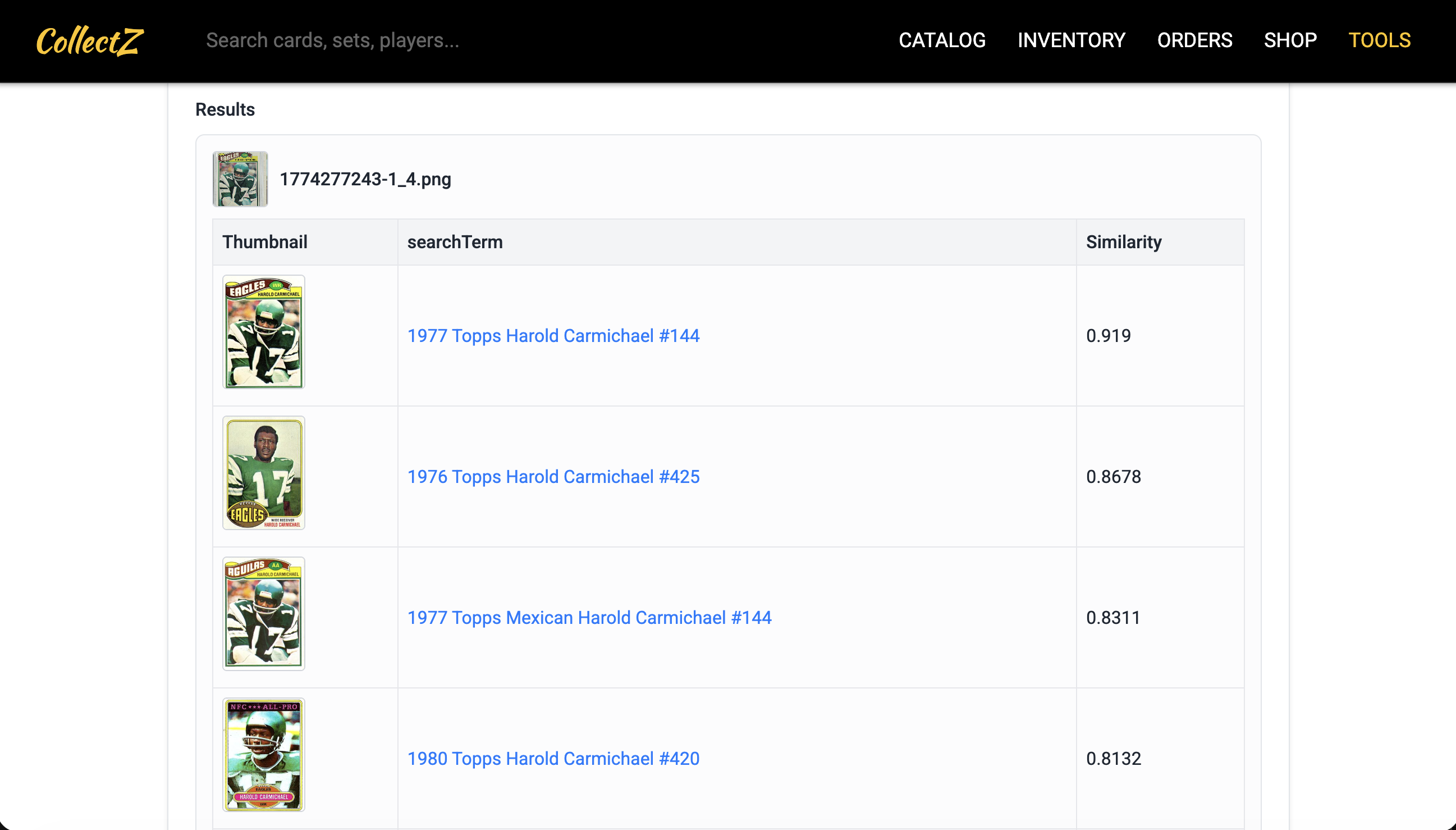
The Card Identifier processing the uploaded card image
What I Learned
A few things stood out from this project:
- Seller photos vs stock images — Cards photographed by sellers (angled, different lighting, sometimes signed) score lower against the clean stock images in the catalog. The system usually identifies the correct player, but may not rank the exact card variant first.
- Variations of cards are hard to distinguish — Many OPC and Topps cards from the same year share the identical front photo and design. Visual similarity alone can't distinguish them — you'd need text recognition or back-of-card analysis for that.
- Thermal throttling is real — Running sustained GPU workloads on a laptop for days requires patience and cooling breaks. My M1 MacBook would drop from 15 cards/sec to 2 cards/sec when it got hot.
- FAISS mmap was the biggest single win — Switching to memory-mapped index loading eliminated multi-second startup overhead without keeping the full index resident in RAM.