
Calculating WeightWatchers points from a picture of the Nutritional Information

When I have tried to track the food I am eating as part of a diet, entering the key nutrition elements was not always convenient. Since I haven't seen a WeightWatchers product for reading nutritional values from a picture, I thought it would be a cool thing to prototype.
One of the guys in my office had a box of oatmeal packets on his desk, so he took a picture with his iPhone 5 - (oatmeal_photo.JPG (2.99 mb)). Below is a lower resolution version:

I had never previously done anything at all with OCR, so I knew I'd learn at the very least. I googled looking for open source OCR libraries and web sites that parsed text from images. I tried quite a few and got the best results from the tesseract project:
https://code.google.com/p/tesseract-ocr/
I banged out a quick powershell script to:
- Execute tesseract to output a text file.
- Parsed the output file for values for Servings, Protein, Carbohydrates, Fat, and Fiber
- Calculated the WeightWatchers Points valuations based on these values.
Although I am unable to share my code with everyone, here's my PowerGUI screen showing the output from the prototype:
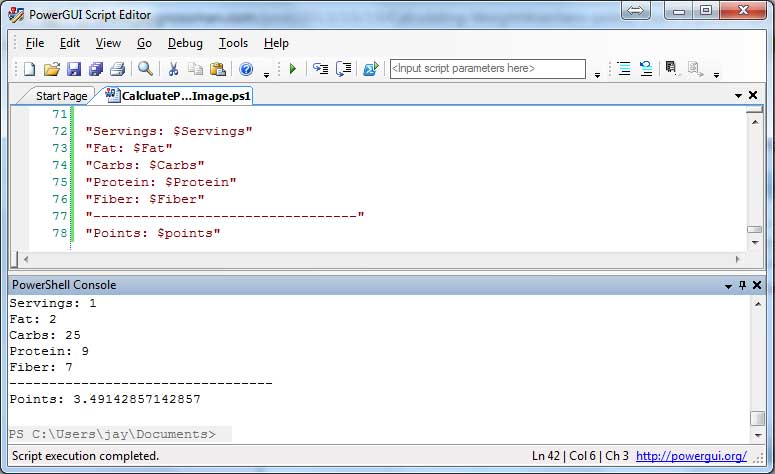
Conclusions:
- I am really psyched I was able to get this functionality working in under 3 hours. It's really important to do this kind of exercise from time to time.
- None of the OCR options I found were anywhere close to perfect at parsing all the text from this image. There's a bunch of assumptions and fuzzy logic transformation rules that a production quality version would require.
- I tried to run some of the libraries with other pictures. I realized quickly that picture quality (size, resolution, and clarity) and lighting glares make a huge difference on how accurately the text in the image gets recognized. This is not a trivial challenge in production!
- I was pleasantly surprised that tesseract was able to understand most of the text on the page, including the text written sideways on the right side of the picture.